挺久之前读的, 补个笔记. 传统机器学习. 从帖子的多个文本来源抽取候选标签, 然后用分类模型判断标签是否与帖子相关. 没有用到图片信息 (除了从图中抽取文字).
LLM-based Text2SQL
Gao, D., Wang, H., Li, Y., Sun, X., Qian, Y., Ding, B., & Zhou, J. (2023). Text-to-sql empowered by large language models: A benchmark evaluation. arXiv preprint arXiv:2308.15363.
个人总结: 一篇 LLM 在 Text2SQL 数据集上的 prompt engineering 的实验报告. 在文中评测的两个数据集中效果是开源方案中最好的. 提出的 prompt 方案 DAIL-SQL 融合了现有的几种 RAG 方法.
A Guide for Customizing Difficulty in Tactics Ogre One Vision Mod
This guide will walk you through using cheat codes to tailor—and particularly increase—the challenge level in Tactics Ogre: Let Us Cling Together (PSP), with a focus on the One Vision mod.
读论文: Direct Fact Retrieval from Knowledge Graphs without Entity Linking
Baek, J., Aji, A. F., Lehmann, J., & Hwang, S. J. (2023). Direct Fact Retrieval from Knowledge Graphs without Entity Linking. arXiv preprint arXiv:2305.12416.
简单粗暴的召回 + 排序. 流程是标准的, 粗暴点 (“创新点”) 在于直接输入句子与知识库中的东西算相似度. 两句话讲完.
膝盖和肩膀如何工作
参考 How does the knee work? 与 How does the shoulder work?, 非常简略. 更多简短补充可以看视频 膝关节结构讲解 与 肩关节解剖结构讲解.
Notes on Introduction to Deep Reinforcement Learning
材料初步考察
- 蘑菇书 的形式和编排结构很好, 但数学部分糟糕 (第二章开头就一堆错误, 反正我读不下去).
- Sutton 的经典 Reinforcement Learning: An Introduction 2022 年的第二版. 主要是 value-based, 而非当今流行的 policy-based (书中只有二十几页描述). 没读.
- HuggingFace 也有个 deep-rl-class. 过于简化了而且比较啰嗦, 但是附方便的代码实践.
- OpenAI 的 Spinning Up 简单介绍了 policy gradient.
- CS 285 at UC Berkeley Deep Reinforcement Learning 比较现代. 看了前面一部分. (视频没看, 直接看的 slides.)
- 其他可以参考 Reinforcement Learning Resources — Stable Baselines3.
下面是简要的笔记: 统一了记号, 自己简明的证明和 PyTorch 实现, 还有杂七杂八的补充.
目标
Which algorithms? You should probably start with vanilla policy gradient (also called REINFORCE), DQN, A2C (the synchronous version of A3C), PPO (the variant with the clipped objective), and DDPG, approximately in that order. The simplest versions of all of these can be written in just a few hundred lines of code (ballpark 250-300), and some of them even less (for example, a no-frills version of VPG can be written in about 80 lines). 来自 Spinning Up.
先搞清楚最流行的方法. 至于具体应用场景… 呃… 我没有需求, 就是单纯玩玩而已, 所以不会特别深入, 看多少算多少.
Heavily modded XCOM2
写得一坨了, 只能自己看看了, 很多看过的材料没贴上来. 目前稳定 250 mod.
PTCG 卡组类型
简介 HiTIN: Hierarchy-aware Tree Isomorphism Network forHierarchical Text Classification
Zhu, H., Zhang, C., Huang, J., Wu, J., & Xu, K. (2023). HiTIN: Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification. arXiv preprint arXiv:2305.15182.
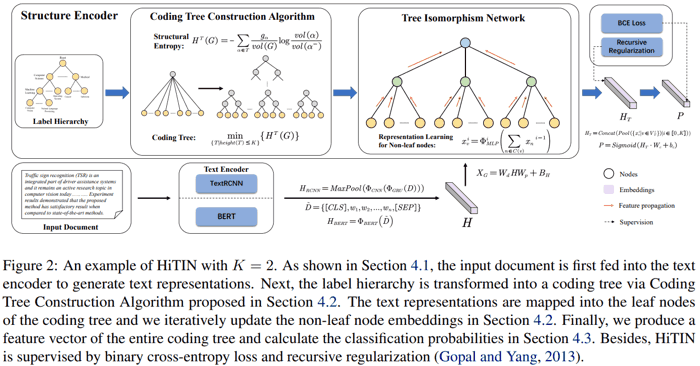
- (左上两个图) 先把原始的类别层级树结构转换成新的树结构 coding tree (作者自创概念).
- 获得文本表示之后 (上图右下 $H$), 转换成 coding tree 叶结点的 embedding (上图 $X_G$, 维度为 (叶结点数, 叶结点 embedding size)).
- (第一行第三个图) 然后用常规的 GNN, 在 coding tree 上, 从底向上, 递归地根据子结点的 embedding 获得结点的 embedding (子结点 embedding 先求和再 MLP). 最后把每一层的结点 embedding 做 pooling (上图右上 $H_T$), 拼接起来, 经过线性层得到最终 logits (标准的多标签分类).
主要创新点是上述第一步. 论文结果中, 相比其他针对层次分类的网络, 本网络参数少而且效果好很多.
重写的代码见 这里.
GPT 微调指南要点
主要参考 Fine-tuning - OpenAI API, 其他补充放在文末.
这个指南大概也能当成其他 LLM 的微调指南.