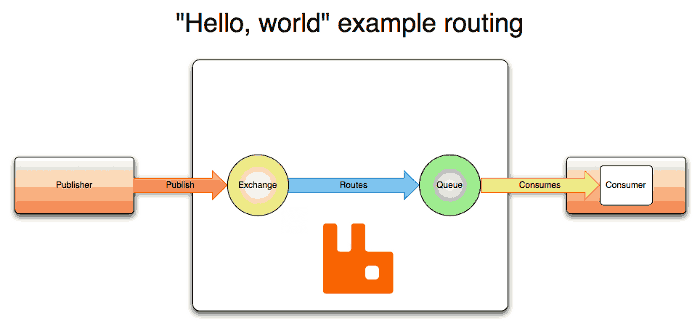
同事看表格检测的文章
- Tensmeyer, C., Morariu, V. I., Price, B., Cohen, S., & Martinez, T. (2019, September). Deep splitting and merging for table structure decomposition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 114-121). IEEE.
中的 Split Model 的 Inference 那节. 文章采用的表格检测分为两步, 先划若干条竖直线和水平线将图像分割为许多单元格, 再合并单元格得到表格.