起点是 ChFinAnn 数据集, 和它的 SOTA 榜单. 其中
- Zhu, T., Qu, X., Chen, W., Wang, Z., Huai, B., Yuan, N. J., & Zhang, M. (2021). Efficient Document-level Event Extraction via Pseudo-Trigger-aware Pruned Complete Graph. arXiv preprint arXiv:2112.06013. [Code]
看起来很不错, 模型比其他人轻量很多, 训练资源要求少 (对比 Doc2EDAG 等涉及到动态建立图神经网络的巨大计算资源需求), 推理速度也快, 效果和其他人相当.
事件抽取
每个事件有这些要素: 事件类型 (比如 “股东增持”), 事件角色 (比如 “增持方”, “交易股份数量” 等多个预先定义的字段), 事件论元 (arguments, 事件角色对应的实体, 比如 “xx公司”, “oo股” 等).
此外还可能有触发词 (triggers), 帮助识别事件类型.
文档级 (篇章级) 事件抽取的两大难点是 (1) 一个事件的论元可能散布在多个句子中 (一篇文档由多个句子组成) (2) 一篇文档包含多个事件.
数据集
- ChFinAnn: Ten years (2008-2018) ChFinAnn documents and human-summarized event knowledge bases to conduct the DS-based event labeling.
- CCKS 2020 面向金融领域的篇章事件要素抽取: 互联网上的新闻文本,上市公司发布的公告文本(PDF文档已转成无结构化的文本内容)
- 千言数据集: DuEE-fin 金融领域篇章级事件抽取数据集
- 其他数据集
PTPCG
Pseudo-Trigger-aware Pruned Complete Graph (PTPCG)
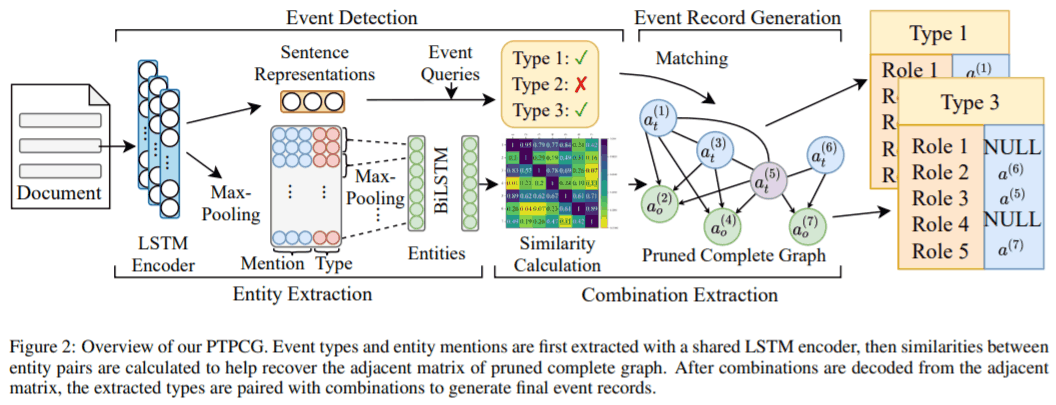
输入文档中所有句子
- 分句后用 BiLSTM encoding
- 事件多标签分类 (图左上的 event detection) 和实体抽取 (第 1 步的 BiLSTM + CRF 序列标注, 然后做一些操作生成实体的表示)
- 计算实体之间语义相似度, 构建一个图 (每个结点是实体, 两个实体之间是否有边取决于相似度是否超过阈值, 详见下一节)
- 完全图 (complete graph) 指所有结点互相连接的图, 而标题中的 pruned 来自这一步: 根据相似度决定是否相连, 达到剪枝目的.
- 从图中解码出每个事件的论元.
- 这一步基于假设: 同一个论元组合中的实体在语义空间中互相接近 (arguments in the same combination are close to each other in the semantic space), 意味着他们在上述构造的图中应当有边连接. 一个论元组合是包含若干实体 (论元) 的集合.
- 先解码出论元组合, 再判断这个组合的事件类型, 以及其中实体对应的事件角色.
图的细节
构造有向图. 记两个实体的表示分别为 $e_i$ 和 $e_j$, 先分别经过不同的全连接层, 即
\[\tilde e_i = W_s e_i + b_s, \quad \tilde e_j = W_t e_j + b_t,\]再求相似度 (基于 $\tilde e_i’ \tilde e_j$). 注意这里的相似度不对称, 所以才能构建有向图.
伪触发词. 构建有向图是为了论文中引入的伪触发词.
在训练前, 根据训练集, 根据文中提出的一种重要度指标生成所有伪触发词. 这个重要度指标是针对每个事件类型的 roles 而言的, 如果一个 role
- 在那个事件类型的所有事件实例中出现 (这个 role 对应的论元非空) 得多,
- 且这个 role 对应的 argument 区分度高 (同一文档中这个论元不会出现在其他事件中),
则这个 role 的重要度指标更高. 伪触发词的数量要事先指定, 比如指定为 $R$ 个, 则从每个事件中各选出 $R$ 个重要度最高的 role; 对每个事件实例, 被选出的 role 对应的论元就是伪触发词.
伪触发词在图中的地位. 实体 (结点) 分为两类: 伪触发词和普通论元. 在前述构造的有向图中, 同一个论元组合中的所有伪触发词之间双向连接, 每个伪触发词指向每个普通论元单向连接. 此外, 每个结点还有自己到自己的连接.
训练时提前知道伪触发词, 预测时需要根据构建出来的图解码出来.
Step 1 先找所有极大团 (用 Bron-Kerbosch 算法), 即找出所有伪触发词; Step 2 3 如图.
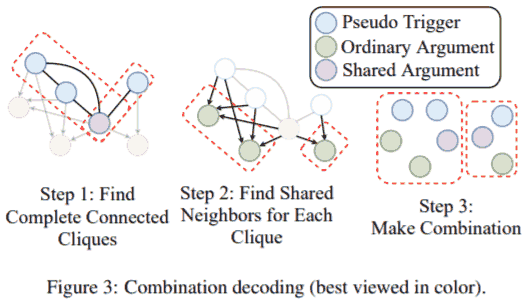
解码出事件. 所有论元组合记为 $C =\{ c_1, \dots, c_n \}$ (上图 $n=2$), 记所有可能的事件类型 $T = \{ t_1, \dots, t_m \}$ (由之前 event detection 那步得到), 对每个 $(t, c) \in T \times C$ 操作.
对 $(t, c)$, 用前馈网络得到 $c$ 中每个实体 $e_i$ 的每个角色 $r_j$ 的概率 $p_{i, j}$. 对每个 role, 取对应概率最大 (需大于阈值 0.5, 否则令论元为空) 的实体作为这个 role 的论元 (一个实体可以作为多个 role 的论元, 但一个 role 只能有一个论元).
相关工作
上面思路很明显分为两个阶段: 先实体识别, 再将实体作为结点构造出图, 从图中解码出事件. 苏剑林也提出过类似的方法, 见 GPLinker:基于GlobalPointer的事件联合抽取.
作者朱桐分享过篇章级事件抽取的相关工作, 见 第三期『千言万语』:篇章事件抽取中的要素组合问题, 讲得很好. 其中 ppt 见 这里.
作者直播答疑原文 (Show more »)
谢谢大家的参与,我回答下刚刚没来得及说的其它问题。如果还有其它问题,欢迎大家留言讨论~
Q1:长度超出512的怎么解决呢
A1:现在的方案大部分用的是切句,以句子为单位先做要素抽取,再做要素组合。如果长度分布超出限制不多的话还是拼接比较好。
Q2:这些内容不需要提前预训练吗
A2:没有使用预训练。基于EDAG的方法如果加了预训练模型会爆显存(32G),训不起来。PTPCG加了预训练模型在DuEE-Fin数据集上单模能到68%左右的水平。
Q3:是沿着上下文匹配到人名就是参与人吗?如果上文是:海绵宝宝要加班来不了。能匹配吗?
A3:在DCFEE中是的,会匹配海绵宝宝(如果算是个人名的话hhh)。
Q4:这里也可以考虑用图神经网络吧
A4:GIT中对Doc2EDAG表示增强的方法主要就是图神经网络;而在PTPCG中,目的是还原一个图结构,所以就没做GNN了。可以使用GNN对已经构成的图做表示增强。
Q5:金融领域事件抽取的可用数据集只有这两个吗
A5:推荐使用百度千言DuEE-Fin和ChFinAnn。此外CCKS2020评测任务中也有篇章事件抽取任务,但是没有公布测试集。
Q6:是不是有点像spo?
A6:如果有触发词的话,也可以把要素组合方案看成一个三元组抽取过程,(触发词,要素角色,要素)。事实上已经有人做过相关工作了。
Q7:这些方法中,有没有使用预训练语言模型?
A7:可参考回答A2
Q8:不同事件间的要素会被打乱吗
A8:不会刻意打乱,但是不能保证输出的结果中要素一定是按原文顺序排列的,因为实体抽取后,要对mention做max-pooling,所以位置信息没有很好地利用到其实
Q9:实体抽取完之后的类别和要素角色是怎么对应
A9:这里只用了实体的类别,查表得一个类别embedding之后,直接和mention表示相加了,和要素角色并没有硬约束关系。
Q10:请问在句子级别事件抽取任务上表现如何
A10:没有做过测试
Q11:有做过基于few shot的实验吗?
A11:没有。全量数据上的效果还不是太好,few-shot估计很难
Q12:是否可以结合提示学习来做
A12:可以的,前提是用预训练模型,可以把prompting作为一个输入增强。不过我没做过测试
Q13:如果伪触发词角色对应的要素为空怎么办?
A13:那么只能为空了。如果全为空,不能构成任何组合的话,我们会加一个“默认组合”,即把所有的实体看成一个大组合
Q14:PTPCG模型会比百度的uie效果更好吗
A14:不好意思,没做过对比,如果有尝试过的同学欢迎讨论
Q15:请问如何看待金融事件类型繁杂的问题
A15:其实金融事件类型太少了还是,一些通用EE数据集中的类别会更多,上百种的也有
Q16:请问和UIEUIE相比效果如何
A16:请参考回答A14
Q17:实体的mention在不同事件有不同含义直接池化是否会带来影响
A17:还是有影响的,GIT中做了更多的尝试,对表示做了更多的增强,可以参考一下
Q18:有无事件抽取的baseline
A18:可以参考PaddleNLP中的事件抽取baseline,或者把今天提到的模型作为baseline尝试一下