即使 BERT 诞生好多年, 这两个依然可用, 因为快小好, 比如 这个.
TextCNN
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. arXiv preprint arXiv:1408.5882.
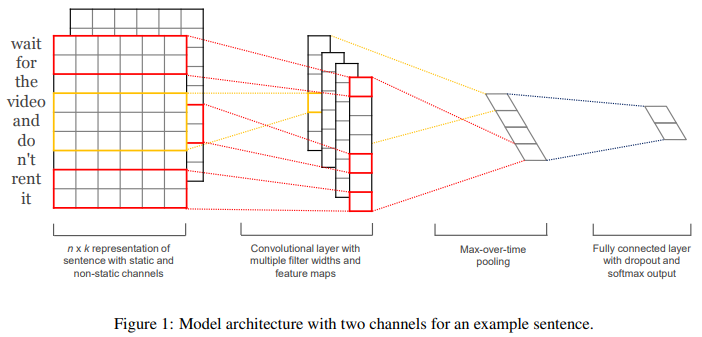
每个卷积核对连续的若干个词向量卷积, 然后通过 max pooling 得到一个值 (一个卷积核对应一个值, 或者说一个 “特征”), 最后全连接完事.
调参技巧: 翻译
fastText
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the association for computational linguistics, 5, 135-146.
- Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2016). Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759.
输入的是 n-gram, 以及词本身, 得到向量再求和. 值得注意的是为了控制参数量, 对这些输入做了 hash (用的是 FNV-1a hash)