Three easy pieces refer to virtualization, concurrency, and persistence. 其他两部分只看了头几节, 暂时不看了.
- Arpaci-Dusseau, R. H., Arpaci-Dusseau, A. C., & Reiher, P. (2018, August). Operating Systems: Three Easy Pieces (Version 1.00). University of Wisconsin-Madison.
进程
一个进程就是一个运行着的程序.
虽然只有几个物理 CPU, how can the OS provide the illusion of a nearly-endless supply of CPUs?
用分时 (time sharing) 解决问题: OS creates this illusion by virtualizing the CPU, 即运行一个程序, 停止它再运行另一个程序, 周而复始.
虚拟 CPU 的实现. We call the low-level machinery mechanisms; mechanisms are low-level methods or protocols that implement a needed piece of functionality. On top of these mechanisms reside policies, which are algorithms for making some kind of decision within the OS. 底层的机制回答了怎么做, 而上层的策略则选择用什么做.
进程的组成部分
OS 对一个运行着的程序的抽象称为一个进程. 进程的 machine state: what a program can read or update when it is running.
- Address space: the memory that the process can address. (Instructions, and the data the running program reads and writes, lie in memory.)
- Registers. 一些特殊的寄存器: program counter (PC) (sometimes called the instruction pointer or IP) 告诉程序下一步执行什么指令; a stack pointer and associated frame pointer are used to manage the stack for function parameters, local variables, and return addresses.
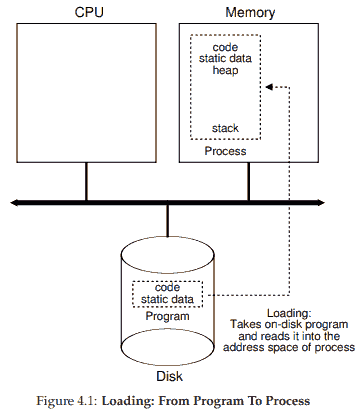
从程序到进程
创建进程 (让程序跑起来, 从而变成进程):
- 将代码和静态数据 (比如初始化变量) 从磁盘载入地址空间;
- 分配一些内存作为程序的 stack (run-time stack) 和 heap.
- 这两个概念不同于数据结构的堆栈.
- C programs use the stack for local variables, function parameters, and return addresses. In C programs, the heap is used for explicitly requested dynamically-allocated data; programs request such space by calling
malloc()and free it explicitly by callingfree().
- I/O 初始化, 比如 UNIX 系统中, 每个进程都有三个文件标识符 (file descriptors), standard input, output, and errorr; these descriptors let programs easily read input from the terminal and print output to the screen.
- 最后, start the program running at the entry point, namely
main(). The OS transfers control of the CPU to the newly-created process, and thus the program begins its execution.
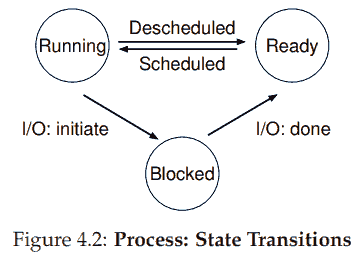
进程状态
- Running: A process is running on a processor. This means it is executing instructions.
- Ready: 可以运行但 OS 没有让它运行.
- Blocked: 典型例子是对磁盘发起 I/O 请求或者在等待网络报文, 进程阻塞, 其他进程得以占用 CPU.
OS 也是一个程序, 通过唯一一个 process list (also called the task list) 来管理进程. 进程的信息存储于 Process Control Block (PCB), 也叫 process descriptor.
另外参考知乎 程序计数器 (Program Counter) 是一个实际存在的寄存器吗?.
进程 API
如何创建和控制进程?
fork() 创建一个新进程. 每个进程有一个进程标识符 (process identifier, PID). 在程序中调用 fork 之后, 就好像是从这里分身出一个一样的进程, 自己调用了 fork 一样, 并且继续执行剩余的指令. while the parent receives the PID of the newly-created child, the child receives a return code of zero.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
sleep(1);
} else {
// parent goes down this path (original process)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
rc, wc, (int) getpid());
}
return 0;
}
wait() won’t return until the child has run and exited. 所以结果一定是子进程先打印. 如果没有 wait, 则打印顺序不固定.
hello world (pid:29266)
hello, I am child (pid:29267)
hello, I am parent of 29267 (rc_wait:29267) (pid:29266)
exec() 应该是来自 execute 的缩写. This system call is useful when you want to run a program that is different from the calling program. It does not create a new process; rather, it transforms the currently running program into a different running program. a successful call to exec() never returns. 转生了
shell 是一个用户程序, 显示一个提示符 (prompt), 然后等待用户输入. 输入命令之后, shell 找到文件中可执行程序的位置, 调用 fork 创建子进程, 调用 exec 的一个变种运行命令, 最后用 wait 等待命令结束. 当子进程运行结束, shell returns from wait(), 再次打印提示符等待下一次输入.
把 fork 和 exec 分开可以让 UNIX shell 在 fork 之后, exec 之前运行代码. This code can alter the environment of the about-to-be-run program.
prompt> wc file > newfile.txt
比如执行上述命令时, shell 创建子进程之后, 关闭标准输出, 打开文件 newfile.txt, 然后再调用 exec. 从而把输出重定向至文件.
另外参考知乎 如何通俗地解释什么是寄存器?, 为什么 Linux 下要把创建进程分为 fork() 和 exec() (一系列函数) 两个函数来处理?.
也有提倡用更简单的 spawn().
分时的机制: Limited Direct Execution
实现分时机制需要解决两个问题: 性能 (减轻系统负担) 和控制 (让 CPU 保持控制).
Problem 1: Restricted Operations
为了使程序运行得快, 基本技术是受限直接执行 (limited direct execution, LDE). 直接执行的意思就是直接在 CPU 上跑程序, 受限指的是不让程序为所欲为. 为此引入新的处理器模式, 用户模式 (user mode), 在该模式下运行会受到限制, 比如不能发起 I/O 请求. 另一个模式称为 kernel mode, 操作系统 (即 kernel) 运行在该模式, 可以做任何事情.
一个用户进程可以通过系统调用 (system call) 执行受限操作, 即执行陷阱 (trap) 指令, 暂时获得 kernel mode 的权限, 做出允许范围内的操作, 之后 OS 调用陷阱返回 (return-from-trap) 指令, 回到原状.

Problem 2: Switching Between Processes
If a process is running on the CPU, this by definition means the OS is not running.
How can the operating system regain control of the CPU so that it can switch between processes?
A Cooperative Approach: Wait For System Calls
OS 信任进程会定期放弃 CPU 的控制, 比如 system calls 或者非法操作 (访问无法访问的地址, 除以零), which will generate a trap to OS. 问题在于如果程序有无限循环怎么办? 重启电脑.
A Non-Cooperative Approach: The OS Takes Control
解决办法是时钟中断 (timer interrupt). 一个 timer device 可以每隔几毫秒 raise 一次中断, 停止当前的进程, 并且在 OS 运行事先设定好的 interrupt handler. 此时 OS 重新获得了 CPU 的控制.
Saving and Restoring Context
OS 获得 CPU 控制后, 调度器 (scheduler) 需要决定继续运行当前进程还是换一个. 如果要换, 那么就需要进行 context switch, 也就是保存当前进程的一些寄存器有关值 (registers, PC, and the kernel stack pointer) (在 kernel stack 上), 并且恢复马上运行的进程的寄存器有关值.

OS needs to be concerned as to what happens if, during interrupt or trap handling, another interrupt occurs. This is the topic of the entire second piece of this book, on concurrency.
调度策略
之前讲了运行进程的底层机制, 现在讲上层调度策略. 要了解调度策略, 需要了解 workload, 先从一些不现实的假设讲起, 逐步过渡到真实情形.
假设, 其中 jobs 是进程的另一种称呼.
- Each job runs for the same amount of time.
- All jobs arrive at the same time.
- Once started, each job runs to completion.
- All jobs only use the CPU (i.e., they perform no I/O)
- The run-time of each job is known.
选用的指标是周转时间 (turnaround time), 即进程完成时刻减去进程进入系统的时刻.
如果先到先得, 前面的进程要运行很长的时间, 会导致后面的进程被卡着, 最终进程平均周转时间被拉长, 这称为 convoy effect. 解决办法是 Shortest Job First (SJF), 让快的人先上. 在前述假设和指标下, 这显然是最优的.
新问题是, 如果快的人晚一点到, 依然会被前面慢的人卡住. 为此, 我们放松假设 3 (that jobs must run to completion). Shortest Time-to-Completion First (STCF) or Preemptive Shortest Job First (PSJF). 正如之前说过, OS 可以定期打断运行, 然后决定是否换一个人跑.
下面考虑新指标, 响应时间 (response time), 即进程第一次被调度的时刻减去进程进入系统的时刻. 前面的算法无法保证合理的响应时间, 引入 Round-Robin (RR). RR runs a job for a time slice (时间片) (sometimes called a scheduling quantum) and then switches to the next job in the run queue. 因此 RR 也叫 time-slicing. Note that the length of a time slice must be a multiple of the timer-interrupt period. 虽然时间片小可以让平均响应时间短, 但是太小的话, context switching 会 dominate 整体性能. 另外, 如果把两个指标同时考虑, 就需要对效率和公平做一些取舍.
切换进程的代价. Note that the cost of context switching does not arise solely from the OS actions of saving and restoring a few registers. When programs run, they build up a great deal of state in CPU caches, TLBs, branch predictors, and other on-chip hardware. Switching to another job causes this state to be flushed and new state relevant to the currently-running job to be brought in, which may exact a noticeable performance cost.
接着放松假设 4 (执行 I/O). 之前讲过, 发起 I/O 请求时, block 当前进程, 把 CPU 让给其他人. I/O 完成之后, 只考虑之前的进程要用的 CPU 时间, 按照之前讨论的调度策略操作.
The Multi-Level Feedback Queue
最著名的调度方法, 多级反馈队列 (MLFQ). The multi-level feedback queue is an excellent example of a system that learns from the past to predict the future.
MLFQ 有若干不同的队列, 每个队列带有不同的优先级 (priority level).
- Rule 1: 根据进程的优先级决定运行哪个.
- Rule 2: 如果优先级相同, 则用 round-robin.
那么关键就是如何设置优先级. MLFQ 通过观察到的行为决定优先级 (根据历史预测未来), 并且会实时调整优先级.
Attempt 1: How To Change Priority
To do this, we must keep in mind our workload: a mix of interactive jobs that are short-running (and may frequently relinquish the CPU), and some longer-running “CPU-bound” jobs that need a lot of CPU time but where response time isn’t important.
- Rule 3: 当进程进入系统, 设置为最高优先级. It doesn’t know whether a job will be a short job or a long-running job, it first assumes it might be a short job, thus giving the job high priority.
- Rule 4a: 如果一个进程使用了一整个时间片, 则降低一级优先级.
- Rule 4b: 如果一个进程在一个时间片之中放弃 CPU, 保持优先级.
有几个问题
- starvation: 如果 interactive jobs 足够多, 他们会霸占所有 CPU 时间, 让那些需要时间长的人永远拿不到 CPU (starve).
- 通过在一个时间片之中故意放弃 CPU 来欺骗 OS, 以保持优先级, 获得资源.
- 程序的行为可能会改变, 比如从 CPU-bound 变成交互. 但上述方式并不能很好地处理这个问题.
Attempt 2: The Priority Boost and Better Accounting
- Rule 5: 在某个时间段之后, 把系统中所有进程的优先度都拉满. 这样就没有人挨饿了, 并且如果程序从 CPU-bound 变成交互, 也会得到合理的处理.
最后一个问题是欺诈 OS 的操作. 解决方法是使用 better accounting of CPU time at each level. 重写规则
- Rule 4: 每当一个进程用尽了在当前等级下分配的 CPU 时间, 就降低其一级优先级.
大多 MLFQ 变种的不同优先级的队列的时间片长短不同, 高优先级的交互式任务时间片短, 而低优先级的 CPU-bound 任务时间片长.
Proportional Share
另一种调度策略, 也叫 a fair-share scheduler. 目标是 try to guarantee that each job obtain a certain percentage of CPU time. An excellent early example is lottery scheduling: every so often, hold a lottery to determine which process should get to run next; processes that should run more often should be given more chances to win the lottery.
用 tickets 表示一个进程应该得到的资源份额, 谁拿的 tickets 多, 谁更可能拿到资源.
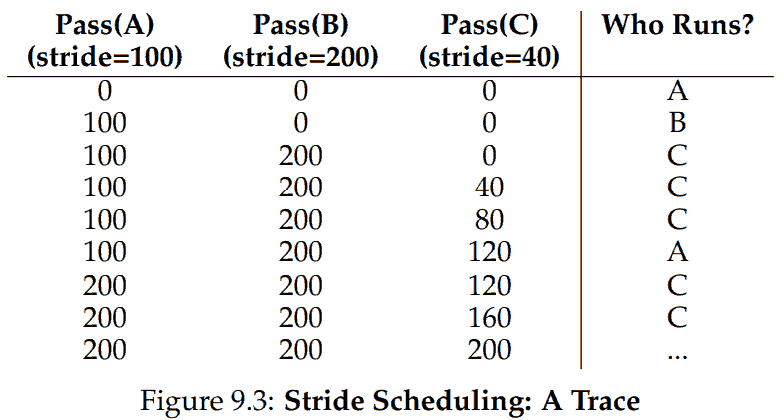
类似地, 有非随机的策略 stride scheduling. 每当一个进程维护一个计数器, 操作系统运行计数最小的进程. 进程运行结束后, 它的计数器增加一个固定值 (每个进程不一样). Lottery 虽然随机, 但好处是没有全局状态. 比如当有新进程进入系统的时候就方便得多.
现代 Linux 系统用了另一种策略 Completely Fair Scheduler (CFS). Its goal is simple: to fairly divide a CPU evenly among all competing processes. It does so through a simple counting-based technique known as virtual runtime (vruntime).
As each process runs, it accumulates vruntime. In the most basic case, each process’s vruntime increases at the same rate, in proportion with physical (real) time. When a scheduling decision occurs, CFS will pick the process with the lowest vruntime to run next. 下略
多处理机调度
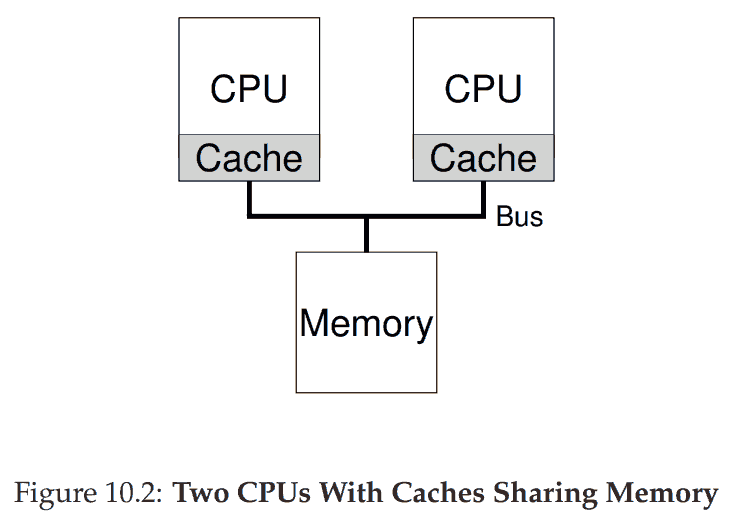
与单 CPU 的区别在于缓存变复杂了. 比如一个进程先在左边 CPU 上运行, 读取数据 D, 缓存了 D. 程序修改数据为 D’, 因为传到主存太慢了, 先直接改缓存, 系统通常会等之后再写入主存. 如果此时 OS 切换到另一个在右边 CPU 上跑的进程, 它会读取到老数据 D, 而不是 D’. 这个问题叫做 cache coherence. 基本的解决办法是监控内存读取, 保证缓存正确.
虚拟内存: 地址空间
虽然保存寄存器的内容很快, 但是要保存整个内存的内容就很没效率了. 因此当多进程运行时, 我们都把它们保存在内存中, 通过地址空间保证他们不会互相干扰.
一个进程的地址空间包括了运行中程序的所有内存状态: 程序的代码, 栈 (to keep track of where it is in the function call chain as well as to allocate local variables and pass parameters and return values), 堆 (dynamically-allocated, user-managed memory).
.")
地址空间是 OS 提供的抽象, 即虚拟内存. The program really isn’t in memory at physical addresses 0 through 16KB; rather it is loaded at some arbitrary physical address(es). 相当于 OS 先做了一次映射. In fact, any address you can see as a programmer of a user-level program is a virtual address.
虚拟内存 (virtual memory, VM) 的主要目标
- transparency. OS 对虚拟内存的实现应当对运行程序不可见.
- efficiency. 时间和空间.
- protection. 只能在自己的地址空间内操作, 以保护其他进程不受干扰. 隔离性 (isolation).
Side note: This usage of transparency is sometimes confusing; some students think that “being transparent” means keeping everything out in the open, i.e., what government should be like. Here, it means the opposite: that the illusion provided by the OS should not be visible to applications. Thus, in common usage, a transparent system is one that is hard to notice, not one that responds to requests as stipulated by the Freedom of Information Act.
Memory API
内存管理有两层. 当进程结束时, OS 会自动回收其所有内存. 在每个进程中, 内存分为堆和栈.
- 栈内存, 由编译器自动管理.
- 堆内存, 由程序员手动管理 (申请和释放).
malloc() 传入 size 以申请堆内存, 成功则返回一个新分配的空间的指针, 失败则返回 NULL. free() 传入 malloc() 返回的指针, 以释放内存.
常见错误
- 忘记分配内存. segmentation fault.
- 没有分配足够内存. buffer overflow.
- 忘记初始化分配的内存. 指调用了 malloc 之后没有给新分配的地方填值, 导致之后程序读到这里会读出未初始化的值 (uninitialized read), 行为不受控制.
- 忘记释放内存. memory leak. 注意 garbage collector 此时没用, 只要一段内存还有 reference, 他就不会被回收, 因此现代语言依旧有内存泄露问题.
- 在完事前释放内存. dangling pointer.
- 重复释放内存. double free. 结果是不受控制的.
- 错误调用 free. invalid frees.
Mechanism: Address Translation
讲 hardware-based address translationn, or just address translation for short. 把虚拟内存转换为物理内存.
我们先假设
- 用户的地址空间在物理内存中是连续的 (contiguous).
- 地址空间的大小比物理内存小.
- 每个地址空间大小相同.
Dynamic (Hardware-based) Relocation
这里的 translation 可以理解为数学意义, 即平移.
physical address = virtual address + base
由于在运行后我们依然可以移动地址空间 (OS 可以在程序不运行的时候改变虚拟内存对应的物理内存位置), 这个技术称为 dynamic relocation (或者叫 base and bounds). 所谓的 hardware-based, 是指每个 CPU 上有一对寄存器, base register 和 bounds (or limit) register, 前者用来做 translation 的 base, 后者用来检验物理地址是否合法 (within bounds). 这对寄存器属于 CPU 上的 memory management unit (MMU) 部件.
分段 (segmentation)
在堆内存和栈内存之间有一段空白, 因此之前提到的 base and bounds 方法不够灵活. 解决方法是对地址空间的每一个逻辑分段都搞一对 base and bounds. A segment is just a contiguous portion of the address space of a particular length. 我们自然地有三个分段 code, stack, and heap. 因此这时硬件就需要三对 base and bounds registers.
注意到 stack grows backwards (i.e., towards lower addresses). 因此硬件上的三对寄存器还需要能标识增长方向.
另外为了节约内存, 还可以在地址空间之间共享某些 memory segment, 尤其是 code sharing. 为了保护, 共享的代码只能读取和运行. 硬件上的三对寄存器需要能够标识读写权限.
Free-Space Management
有了分页之后, 管理 free space 很容易. Where free-space management becomes more difficult (and interesting) is when the free space you are managing consists of variable-sized units. 会有 external fragmentation 问题: 可用空间被分成若干小段, 从而无法满足连续空间的请求. 比如 OOXXOO, X 表示使用, O 表示空闲, 就无法满足三个 O 连续空间的请求. 对应的有 internal fragmentation: if an allocator hands out chunks of memory bigger than that requested, any unasked for (and thus unused) space in such a chunk is considered internal fragmentation (because the waste occurs inside the allocated unit) and is another example of space waste.
管理堆内存, 数据结构是某种 free list. This structure contains references to all of the free chunks of space in the managed region of memory. 下面主要考虑 external fragmentation. 假设一旦内存分配给了用户, 它就不能被移动到内存的另一个地方. 以及假设 allocator manages a contiguous region.
Low-level Mechanisms
先讨论分配器 (allocator) 的机制. A free list contains a set of elements that describe the free space still remaining in the heap.
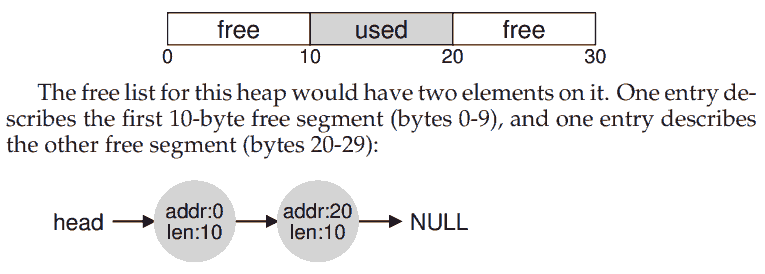
如果请求的空间小于 10 字节, 那么就需要 splitting, 就是找到一块足够大的连续空间, 把请求大小的一块给调用者, 另一块不动. 另一个操作是 coalescing, 就是把实际上连续的空余空间都合成一块.
注意到调用 free 的时候并没有 size 参数, 而只需要给定指针. 实际上大多数分配器会在一个 header block 中 (通常在分配出去的内存块的头上, 需要一点点额外空间) 存储额外的信息, 包括大小. 给定指针之后, 它可以找到 header 的内容, 从而释放内存.
Strategies 略.
分页 (paging)
之前用 segmentation 把东西划分成不等长的块, 会导致 fragmented 问题. 另一种方法是分成固定大小的块, 称为分页 (paging). 每一个块为一页, 可以把物理内存看成一列固定大小的槽 (页框, page frame). 这也让空闲空间管理容易得多, 有请求时只要拿出若干空闲的页就行. 每一个进程配有一个页表 (page table), 用来转换虚拟内存和物理内存.
Because page tables are so big, we don’t keep any special on-chip hardware in the MMU to store the page table of the currently-running process. Instead, we store the page table for each process in memory somewhere. Without careful design of both hardware and software, page tables will cause the system to run too slowly, as well as take up too much memory
Faster Translations (TLBs)
Going to memory for translation information before every instruction fetch or explicit load or store is prohibitively slow. 用硬件帮忙, translation-lookaside buffer, or TLB, 也在 MMU 里, a hardware cache of popular virtual-to-physical address translations.
Hardware caches take advantage of locality by keeping copies of memory in small, fast on-chip memory. Instead of having to go to a (slow) memory to satisfy a request, the processor can first check if a nearby copy exists in a cache; if it does, the processor can access it quickly (i.e., in a few CPU cycles) and avoid spending the costly time it takes to access memory (many nanoseconds). 为了速度快, cache 只能小.
另外参考知乎 Cache 的基本原理.
Mechanism: Swappings
为了支持更大的地址空间, OS 把一部分当前不太需要的地址空间交换到磁盘上. 尤其是 multiprogramming 下, 非常需要这么做.
在磁盘上预留一些空间, 称为交换空间 (swap space), 用以和内存交换 page. OS 需要知道给定 page 的磁盘地址 (disk address).
Given that main memory holds some subset of all the pages in the system, it can rightly be viewed as a cache for virtual memory pages in the system. Thus, our goal in picking a replacement policy for this cache is to minimize the number of cache misses.
后面没怎么看.