- Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., … & Poli, I. (2024). Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference. arXiv preprint arXiv:2412.13663.
- 2024-12-19 Hugging Face Finally, a Replacement for BERT
如同字面意思, 更现代的 BERT, 更快更强而且 context length 拓展到 8k tokens, 也是首个在训练数据中加入大量代码数据的 encoder-only 模型. BERT 系模型对比 LLM 的优势是快, 便宜, 而且很多任务适用 encoder-only 结构.
性能
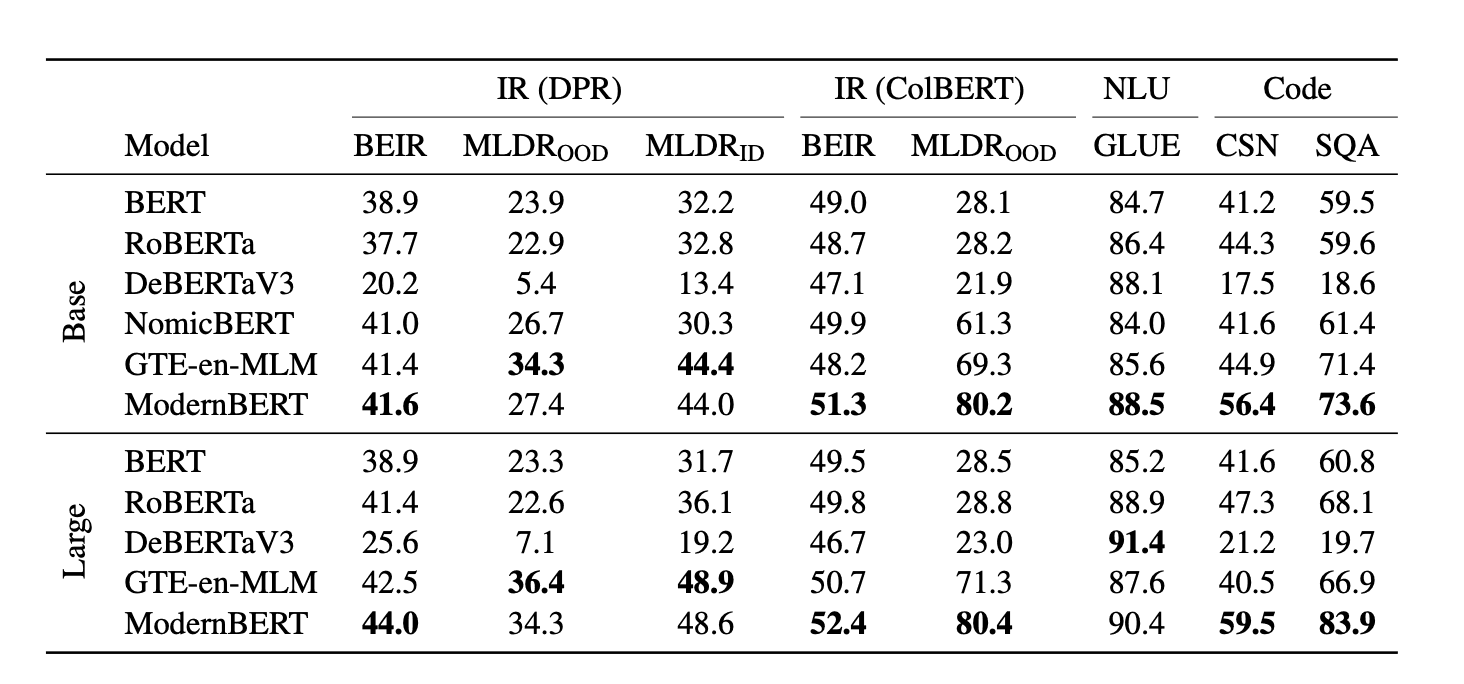
ModernBERT 不仅是首个在 GLUE 中打败 DeBERTaV3 的 base-size 模型, 而且其内存使用量不到 DeBERTa 的五分之一. 速度也是 DeBERTa 两倍, 输入混合长度序列时最高可达到四倍.
Here’s the memory (max batch size, BS) and Inference (in thousands of tokens per second) efficiency results on an NVIDIA RTX 4090 (在消费级显卡上考虑性能) for ModernBERT and other decoder models:
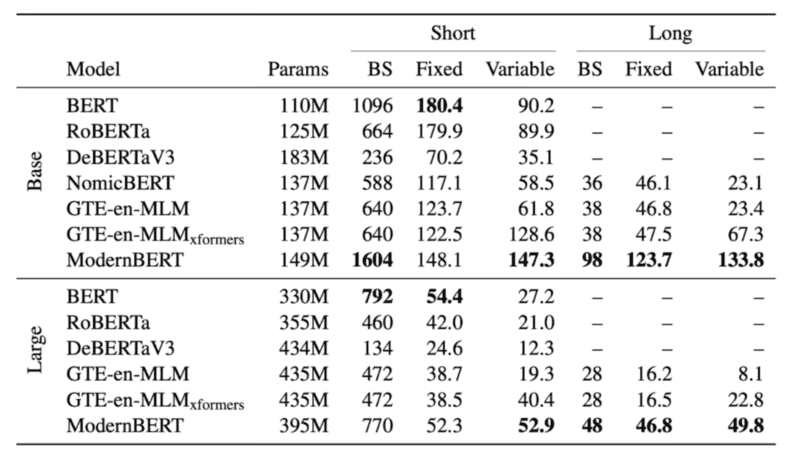
On short context, it processes fixed-length 512 token inputs faster than all other recent encoders, although slower than the original BERT and RoBERTa models. On long context, ModernBERT is faster than all competing encoders, processing documents 2.65 and 3 times faster than the next-fastest encoder at the BASE and LARGE sizes, respectively. On variable-length inputs, both GTE-en-MLM and ModernBERT models are considerably faster than all other models, largely due to unpadding.
Why modern?
Even more surprising: since RoBERTa, there has been no encoder providing overall improvements without tradeoffs (fancily known as “Pareto improvements”): DeBERTaV3 had better GLUE and classification performance, but sacrificed both efficiency and retrieval. Other models, such as AlBERT, or newer ones, like GTE-en-MLM, all improved over the original BERT and RoBERTa in some ways but regressed in others.
The goal of the (hopefully aptly named) ModernBERT project was thus fairly simple: bring this modern engineering to encoder models. We did so in three core ways:
- a modernized transformer architecture
- particular attention to efficiency
- modern data scales & sources (2T tokens)
New transformer
- Replace the old positional encoding with “rotary positional embeddings” (RoPE).
- Switch out the old MLP layers for GeGLU layers, improving on the original BERT’s GeLU activation function.
- Streamline the architecture by removing unnecessary bias terms, letting us spend our parameter budget more effectively. 减少参数
- Add an extra normalization layer after embeddings, which helps stabilize training.
Efficiency
Our efficiency improvements rely on three key components: Alternating Attention, to improve processing efficiency, Unpadding and Sequence Packing, to reduce computational waste, and Hardware-Aware Model Design, to maximise hardware utilization.
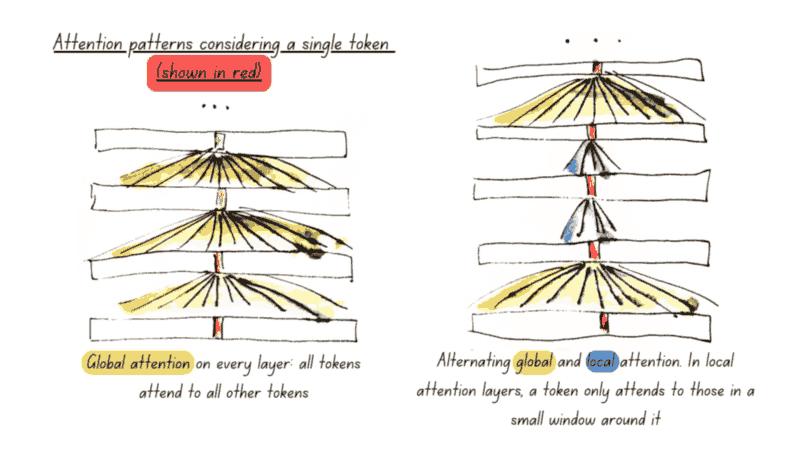
Alternating Attention. In technical terms, this means that our attention mechanism only attends to the full input every 3 layers (global attention), while all other layers use a sliding window where every token only attends to the 128 tokens nearest to itself (local attention).
Unpadding and Sequence Packing.
In order to be able to process multiple sequences within the same batch, encoder models require them to be the same length, so they can perform parallel computation. Traditionally, we’ve relied on padding to achieve this: figure out which sentence is the longest, and add meaningless tokens (padding tokens) to fill up every other sequence.
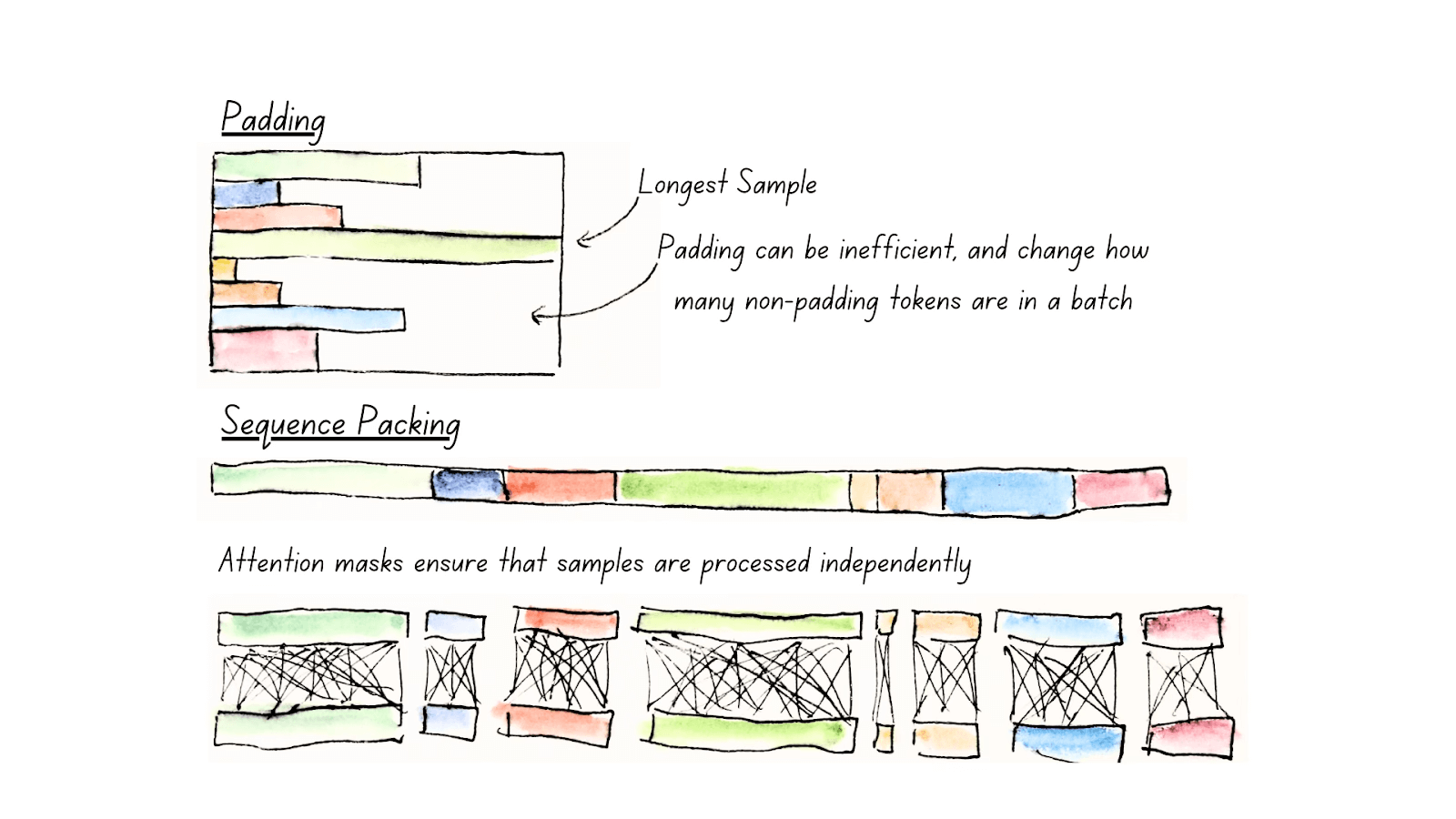
Unpadding solves this issue: rather than keeping these padding tokens, we remove them all, and concatenate them into mini-batches with a batch size of one, avoiding all unnecessary computations. If you’re using Flash Attention, our implementation of unpadding is even faster than previous methods, which heavily relied on unpadding and repadding sequences as they went through the model: we go one step further by introducing our own implementation of unpadding, relying heavily on recent developments in Flash Attention’s RoPE support. This allows ModernBERT to only have to unpad once, and optionally repad sequences after processing, resulting in a 10-20% speedup over previous methods.
Paying Attention to Hardware. 在一组常见的消费级显卡上优化模型结构.
Training
We stick to the original BERT’s training recipe, with some slight upgrades inspired by subsequent work: we remove the Next-Sentence Prediction objective, since then shown to add overhead for no clear gains, and increase the masking rate from 15% to 30%.
Both models are trained with a three-phase process. First, we train on 1.7T tokens at a sequence length of 1024. We then adopt a long-context adaptation phase, training on 250B tokens at a sequence length of 8192, while keeping the total tokens seen per batch more or less consistent by lowering the batch size. Finally, we perform annealing on 50 billion tokens sampled differently, following the long-context extension ideal mix highlighted by ProLong.
Tricks
Let’s start with the first one, which is pretty common: since the initial training steps are updating random weights, we adopt batch-size warmup: we start with a smaller batch size so the same number of tokens update the model weights more often, then gradually increase the batch size to the final training size. This significantly speeds up the initial phase of model training, where the model learns its most basic understanding of language.
The second trick is far more uncommon: weight initialization via tiling for the larger model size, inspired by Microsoft’s Phi family of models. This one’s based on the following realization: Why initialize the ModernBERT-large’s initial weights with random numbers when we have a perfectly good (if we dare say so ourselves) set of ModernBERT-base weights just sitting there?