随便记两篇文章.
InstructUIE
Wang, X., Zhou, W., Zu, C., Xia, H., Chen, T., Zhang, Y., … & Du, C. (2023). InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction. arXiv preprint arXiv:2304.08085.
和之前生成式 UIE 方法差不多, 把不同抽取任务写成比较统一的格式, 再 seq2seq. 现在生成模型换成了更大的 LLM, 所以低资源下更好; 输入输出格式也换了. 宣称的结果是和有监督的 BERT 相仿, zero-shot 上显著超越 GPT-3.5.
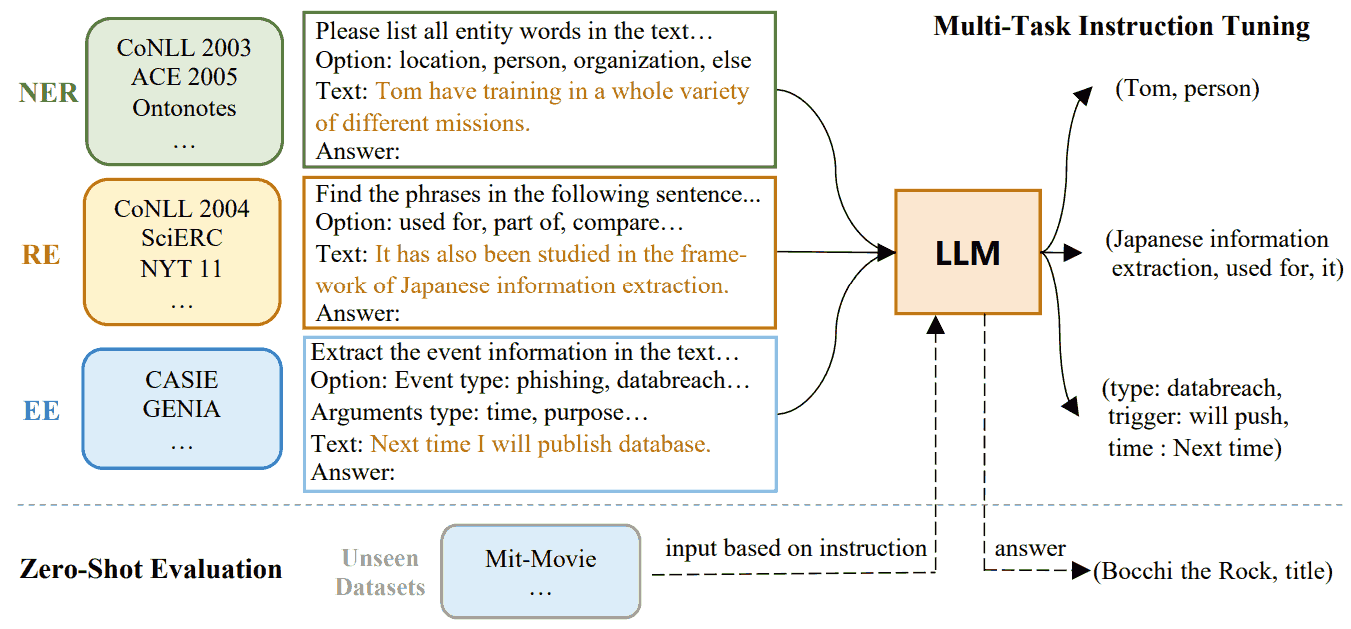
以上图 NER 为例, prompt 中的 option 限定了实体类别.
除了几大主要任务, 每类信息抽取任务增加了一些子任务辅助训练. 以 NER 为例
ES: Please list all entity words in the text that fit the category. Output format is “type1: word1; type2: word2”.
ET: Please find all the entity words associated with the category in the given text. Output format is “type1: word1; type2: word2”.
NER: Please tell me all the entity words in the text that belong to a given category. Output format is “type1: word1; type2: word2”.
- ES refers to entity span, the task target is given sentence and entity category options, and output entities that conform to the entity category, but there is no need to output the entity type of each entity; (这里说只根据给定的类别抽取所有实体, 不关联实体类别, 所以上文他写的输出格式好像不太对?)
- ET refers to entity type identification. The task target is a given sentence, which contains entity and entity category options, and outputs the entity category corresponding to each entity.
- NER refers to the named entity recognition task, the object of which is the entity in the output sentence and its corresponding entity type.
Flan collection
Longpre, S., Hou, L., Vu, T., Webson, A., Chung, H. W., Tay, Y., … & Roberts, A. (2023). The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688.
更大更多样的数据
We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings.
Additionally, enriching task diversity by inverting input-output pairs, along with balancing task sources, are both shown to be critical to performance. For example, a dataset may be originally designed for, given a question x, evaluate if a model can answer y. Input inversion instead gives a model the answer y and trains it to generate the question x. This is an easy method to enrich the task variety given a limited set of data sources. However, it isn’t clear that this method remains helpful when 100s of unique data sources and 1000s of tasks are already available.
Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks—motivating instruction-tuned models as more computationally efficient starting checkpoints for new tasks.