一些摘抄.
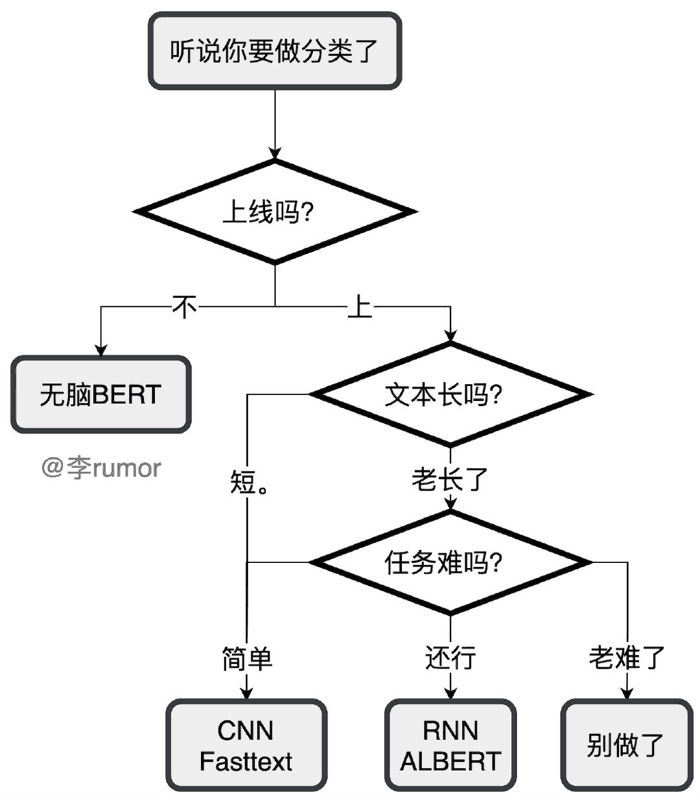
文本分类
标签体系构建 拿到任务时自己先试标一两百条, 看有多少是难确定 (思考 1s 以上) 的, 如果占比太多, 那这个任务的定义就有问题. 可能是标签体系不清晰, 或者是要分的类目太难了, 这时候就要找项目 owner 去反馈而不是继续往下做.
训练评估集的构建 可以构建两个评估集, 一个是贴合真实数据分布的线上评估集, 反映线上效果; 另一个是用规则去重后均匀采样的随机评估集, 反映模型的真实能力.
数据清洗
去掉文本强pattern:比如做新闻主题分类,一些爬下来的数据中带有的XX报道、XX编辑高频字段就没有用,可以对语料的片段或词进行统计,把很高频的无用元素去掉。还有一些会明显影响模型的判断,比如之前我在判断句子是否为无意义的闲聊时,发现加个句号就会让样本由正转负,因为训练预料中的闲聊很少带句号(跟大家的打字习惯有关),于是去掉这个pattern就好了不少
纠正标注错误:这个我真的屡试不爽,生生把自己从一个算法变成了标注人员。简单的说就是把训练集和评估集拼起来,用该数据集训练模型两三个epoch(防止过拟合),再去预测这个数据集,把模型判错的拿出来按 abs(label-prob) 排序,少的话就自己看,多的话就反馈给标注人员,把数据质量搞上去了提升好几个点都是可能的
小样本 先无脑 BERT 训一版. 如果样本在几百条, 可以先把分类问题转化成匹配问题, 或者用这种思想再去标一些高置信度的数据, 或者用自监督/半监督的方法.
- 李rumor. (2021). 在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
链接里包括一些调参经验.
- 李rumor. (2021). 目前深度学习用在短文本分类最好的模型有哪些?
模型选型 推荐的算法选型为
- Fasttext (垃圾邮件/主题分类) 特别简单的任务, 要求速度
- TextCNN (主题分类/领域识别) 比较简单的任务, 类别可能比较多, 要求速度
- LSTM (情感分类/意图识别) 稍微复杂的任务
- Bert (细粒度情感/阴阳怪气/小样本识别) 难任务
一个特别经典的结构建议大家试一下: concat_emb -> spatial dropout(0.2) -> LSTM -> LSTM -> concat(maxpool, meanpool) -> FC. 除了经典结构, 几乎所有的吊炸天 structure 可以被精调的两层 lstm 干掉.
关于这个双层结构的注释 (Show more »)
在很多地方看到过这个, 不清楚具体叫什么.
结合策略和算法
- 串行式. 典型的代表是, 规则捕捉-分类-匹配 (以搜代分) 兜底, 大概这样的流程会比较合理. 规则部分负责解决高频, 和 bad/hard case, 分类负责解决长尾中的头部, 匹配负责解决长尾.
- 并行式. 规则, 分类, 匹配都过, 归一化后的置信度进行 PK, 有点类似于广告竞价, 这样的好处是能充分融合多重策略, 结果更可靠.
以上
- 包包大人. (2022). 工业界文本分类避坑指南
- 包包大人. (2022). 在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
TextCNN 作基线, CNN 实现简单跑得快, 可以多跑几组. Tricks 用得好, 调参调得妙, TextCNN 也能吊打绝大多数花里胡哨的深度模型.
如果数据集里很多很强的 n-gram 可以直接帮助正确决策, 那就 CNN 起步; 如果很多 cases 要把一个句子看完甚至两三遍才容易得出正确 tag, 那就 RNN 起步.
多标签分类 如果一个样本有 N 个标签, 先当做 N 个二分类任务跑 baseline, 然后可能发现没啥问题了. 什么? 问题木有解决? 去查论文吧╮( ̄▽ ̄””)╭小夕还没有接触过这方面太难的数据集.
类别不平衡 正负样本比才 9:1 的话, 这点不均衡对模型来说不值一提, 决策阈值也完全不用手调. 但是, 如果发现经常一个 batch 中完全就是用一个类别的样本, 或者一些类的样本经过好多 batch 都难遇到一个的话, 均衡就非常有必要了.
- 夕小瑶. (2019). 在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
- Zhang, Y., & Wallace, B. (2015). A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv preprint arXiv:1510.03820.
在构建模型时, 由于意图识别模块对速度的要求大于精度, 所以一般会用很浅的模型, 比如统计方法或者浅层神经网络. 在 微信 和 第四范式 的分享中都提到说 Fasttext 的效果就很好了. 在浅层模型下要想提升效果, 可以增加更多的输入信息, 比如微信就提供了很多用户画像的 feature.
- 李rumor. (2021). 业界总结|搜索中的Query理解
多级分类做意图识别是业界标准操作.
附注: 同级别 Albert 虽然参数少, 但是推理时间一样, 同等计算量下不如 BERT, 不推荐.
- DASOU. (2020). 模型工业落地(三)-Albert究竟能不能上线?能!耗时如何?20ms!
未来得及整理: JayJay. (2020). 如何解决NLP分类任务的11个关键问题:类别不平衡&低耗时计算&小样本&鲁棒性&测试检验&长文本分类
NER
设计任务时, 尽量不引入嵌套实体, 不好做, 这往往是长尾问题.
不要把赌注都压在模型上, 而应该从流程和架构的角度, 多设计几个模块. 这样可以极大提高整个解决方案的可控性和可解释性, 让黑盒属性的占比降低.
(单层) BiLSTM-CRF 几乎是非常可靠的基线, 再配合规则 + 领域词典. 单层 LSTM 足以捕捉方向信息和局部特征. 要继续优化可以在 embedding 上下功夫, 引入更多特征, 如 char, bigram, 词性特征等.
- wei chris. (2021). NLP领域内,文本分类、Ner、QA、生成、关系抽取等等,用过的最实用、效果最好的技巧或思想是什么?
- JayJay. (2021). 工业界如何解决NER问题?12个trick,与你分享~
其他
美团用 IDCNN-CRF 蒸馏 BERT, 不过之前 JayJay 则是不推荐蒸馏.
- 美团. (2020). 美团搜索中NER技术的探索与实践
关系抽取
- JayJay. (2020). nlp中的实体关系抽取方法总结
Paddle 的 WordTag-IE 工具
- Severus. (2022). 破局数据困境,迭代一年的终版解决方案竟是纯规则方法!
其他
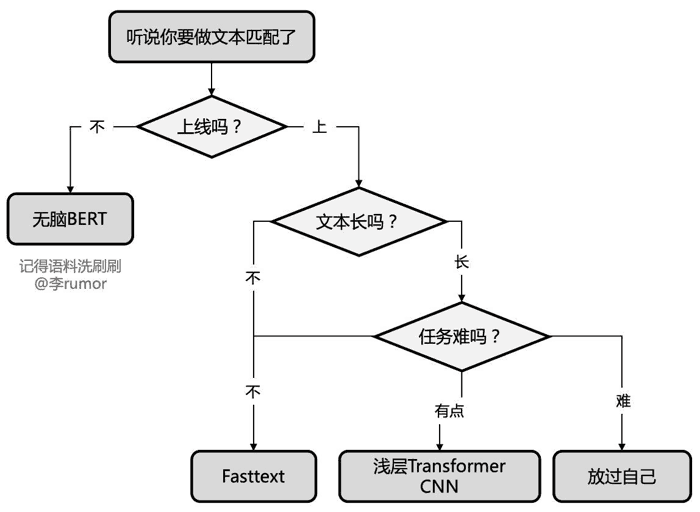
千万不要小看词向量, 用好了真的是很强的 baseline. 另外现在很多线上场景因为对速度要求高, 或者是 toB 的业务甲方不愿意买 GPU, 有不少落地都停留在这个阶段.
- 李rumor. (2021). 短文本匹配有什么好的方法?
- 李rumor. (2021). 现在工业界有哪些比较实用的计算短文本相似度的算法或者模型?
- 李rumor. (2022). 21个经典深度学习句间关系模型|代码&技巧
在项目早期资源匮乏的情况下, 规则和词典是主流. 要上模型时先搭建 baseline 模型 (fasttext, textcnn, bilstm-crf 等) 上线, 后续跟随数据, 特征, 训练策略的优化进行迭代, 等逐步触碰到天花板的时候, 再来考虑上更大的模型甚至是预训练模型. 这个节奏的优势是, 收益提升稳定, 风险也可控. 如果直接上预训练模型, 会出现问题定位困难, 数据特征短板无法发现, 提升不稳定且风险高的问题.
- 机智的叉烧. (2022). 心法利器 | 规则到模型的过渡和升级策略
大部分 NLP 场景对 OOV 都不会太敏感, 一般能带来的稳定收益很小. 总之, 打出来 OOV 后扫一眼, 只要不是跟任务特别相关, 那就别太纠结啦, 先把其他事儿处理好再回过头照顾一下 OOV 即可.
- 夕小瑶. (2019). Word Embedding 如何处理未登录词?
文本质量高, 噪声小, 用 word 粒度. 互联网用户产生, 文风千奇百怪, 充斥各种语法错误和错别字, 用 char 粒度; 允许使用海量文本训练出的强大预训练模型如 BERT, 那么不用管下游任务怎样, 都果断 char level.
- 夕小瑶. (2018). CNN文本分类中是否可以使用字向量代替词向量?
业务案例
主要看问题拆解和数据收集方法.
- DataFunTalk. (2022). QQ音乐命名实体识别技术
- 微信AI. (2021). 微信看一看如何过滤广告文章?
- 美团. (2021). Query理解在美团搜索中的应用