- Lu, Y., Liu, Q., Dai, D., Xiao, X., Lin, H., Han, X., … & Wu, H. (2022). Unified Structure Generation for Universal Information Extraction. arXiv preprint arXiv:2203.12277.
百度最近铺天盖地地宣传他家的信息抽取方案. UIE 的想法是把各类信息抽取任务统一为以「prompt + 文本」为输入, 用不同 prompt 代表不同任务, 输出生成答案的形式. 这个想法并不新颖, 早在 2019 年谷歌就发过一篇 T5 模型 (目前 3.5k+ 引用), 以 transformer 的 encoder-decoder 为架构, 用多种任务预训练模型, 把任务视为用不同的 prompt 做 seq2seq 的生成任务. T5 的想法其实也不新颖, 不过做的实验特别多, 影响力比较大.
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683. [Code]
下面依次简单讲一讲 prompt, T5, 以及 UIE.
Prompt
Prompt 意思是提示符 (比如 shell 中的 $). 想法来自让下游任务的形式更贴近预训练任务的形式, 提升小样本学习的效果. 目前用于分类和生成任务.
主要有两类:
- 用前缀或者后缀 (prefix prompt), 比较适合自回归 LM 或者生成式. 比如输入 “translate English to German: That is good.”, 输出德语翻译.
- 完形填空 (cloze prompt), 比较适合 masked language model. 比如 “[CLS]我很累, 感觉很[MASK][SEP]”, 输出 [MASK] 对应的字符.
问题是 prompt 需要自己设计, 有时看似差不多的 prompt 产生的结果可能大相径庭. 也有把离散 prompt 换成连续的做法, 但这更是玄学之上再套一层玄学.
- 李rumor. (2021). Prompt 范式的缘起|Pattern-Exploiting Training
- 李rumor. (2021). Prompt 范式第二阶段|Prefix-tuning、P-tuning、Prompt-tuning
- 马杀鸡三明治. (2022). prompt 到底行不行
- JayJay. (2022). 综述|信息抽取的”第二范式”
- 霜清老人. (2022). NLP 中 prompt learning 有哪些可能的天生缺陷?目前有什么样的方法来解决这样的缺陷?
T5
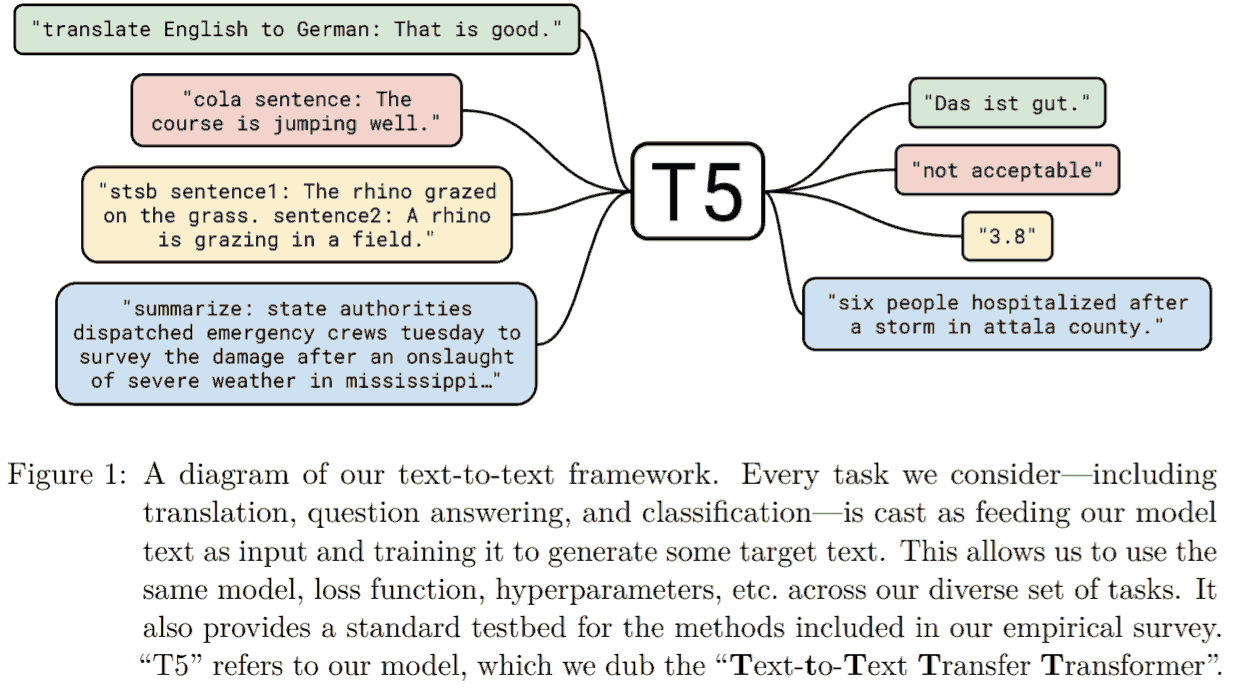
不多讲.
其中 T5 的文本相似度任务是当成分类任务做的 (Show more »)
We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
We were able to straightforwardly cast all of the tasks we considered into a text-to-text format with the exception of STS-B, which is a regression task where the goal is to predict a similarity score between 1 and 5. We found that most of these scores were annotated in increments of 0.2, so we simply rounded any score to the nearest increment of 0.2 and converted the result to a literal string representation of the number (e.g. the floating-point value 2.57 would be mapped to the string “2.6”). At test time, if the model outputs a string corresponding to a number between 1 and 5, we convert it to a floating-point value; otherwise, we treat the model’s prediction as incorrect. This effectively recasts the STS-B regression problem as a 21-class classification problem.
- 苏剑林. (2020). 那个屠榜的 T5 模型, 现在可以在中文上玩玩了
预训练
One needs a dataset that is not only high quality and diverse, but also massive. To satisfy these requirements, we developed the Colossal Clean Crawled Corpus (C4), a cleaned version of Common Crawl (多但低质量) that is two orders of magnitude larger than Wikipedia (少但高质量).
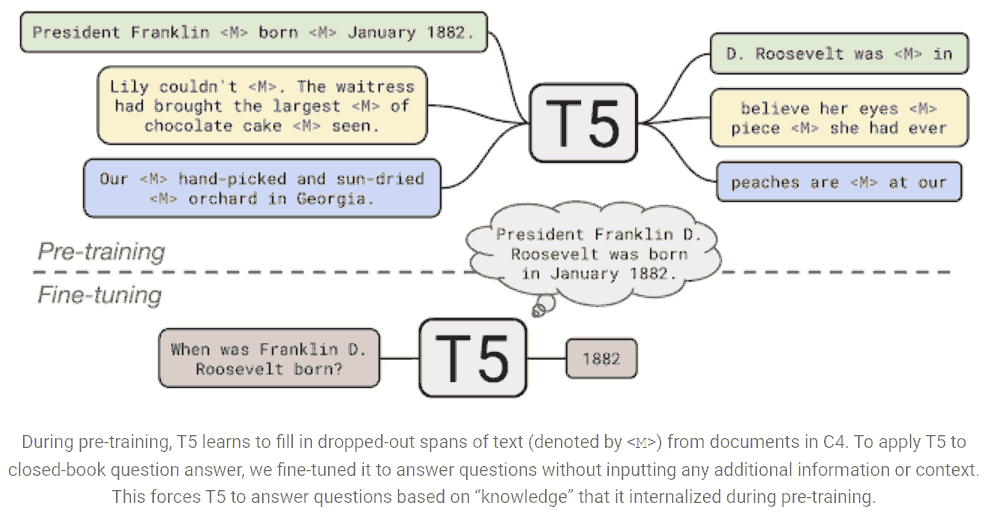
The full details of the investigation can be found in the paper, including experiments on: (Show more »)
- model architectures, where we found that encoder-decoder models generally outperformed "decoder-only" language models;
- pre-training objectives, where we confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost;
- unlabeled datasets, where we showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- training strategies, where we found that multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task;
- and scale, where we compare scaling up the model size, the training time, and the number of ensembled models to determine how to make the best use of fixed compute power.
参考
- Google Research. (2020). Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
UIE
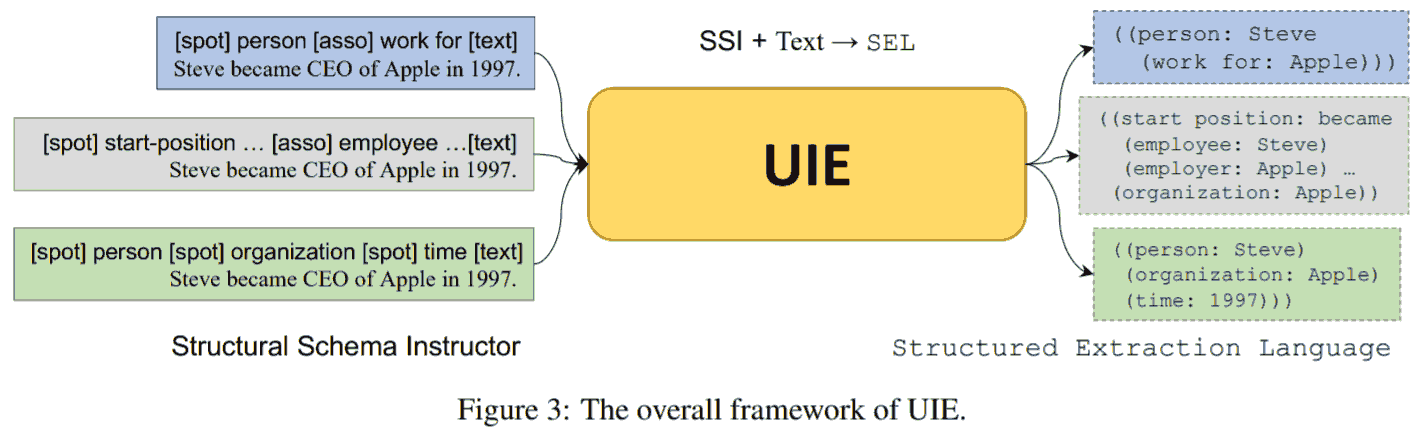
UIE 做的事情就是新提了一系列 prompt 形式, 预训练模型. 涉及的任务包括命名实体识别, 关系抽取, 事件抽取, 情感倾向分类 (文本分类) 等. 他把抽取任务分为两个要素: spotting, 定位实体; associating, 关联实体. 模型的输入构造如下
[spot]...[spot]...[asso]...[asso]...[text]原文
文中将这种 prompt 称为 structural schema instructor (SSI), 这个前缀可以表示成树状形式; 把输出称为 structured extraction language (SEL).
以关系抽取为例, schema 如下
{
'竞赛名称': [
'主办方',
'承办方'
],
'其他字段'
}
其中 “竞赛名称” 是 spot 相当于主语字段, asso 包括 ‘主办方’, ‘承办方’, 相当于谓语, 而 asso 对应的值则是宾语. 其中 asso 关联到 spot 下形成树状结构 (代码也是这么实现的).
输出形式如下
(
(
竞赛名称: XX大赛
(主办方: A协会)
(承办方: B协会)
)
(其他字段: blahblah)
)
预训练任务
有三种.
- Text-to-structure. 对齐 Wikidata 和英文 Wikipedia 构建语料 (SSI, text, SEL). 训练模型整体.
- Masked language model. 用英文 Wikipedia 原文构建语料 (None, corrupted_source_text, corrupted_target_text). 训练语义.
- Structure generation. 从 ConceptNet 和 Wikidata 收集结构化数据构建语料 SEL, 只训练 decoder (自回归生成). 训练生成格式.
总 loss 为上述三个任务 loss (交叉熵) 相加.
使用相关
标注技巧 以中文预训练模型为例. 因为用的字段会放进 prompt 里, 所以字段名需要是中文 (issue#2251), 并且和原文相似 (比如原文出现过的词).
读代码
官方 PyTorch 实现见 这里, 是基于 Google T5 (huggingface 版) 的生成式模型, 提供了中文预训练模型 uie-char-small (chinese), Paddle 版的见 DuUIE. 另外 PaddleNLP 实现了基于 ERINE 3.0 和指针的中文 UIE, 并集成到了 taskflow 接口中, 提供了多种不同大小的预训练模型.
下面贴的代码只提出必要部分并有少量改写.
原版
# inference.py#L36-L62
class HuggingfacePredictor:
def __init__(self, ...):
self._model = (
transformers.T5ForConditionalGeneration.from_pretrained(model_path)
)
def predict(self, text):
text = [self._ssi + x for x in text]
inputs = self._tokenizer(text, ...)
result = self._model.generate(...)
return self._tokenizer.batch_decode(result, ...)
PaddleNLP 2.3.0
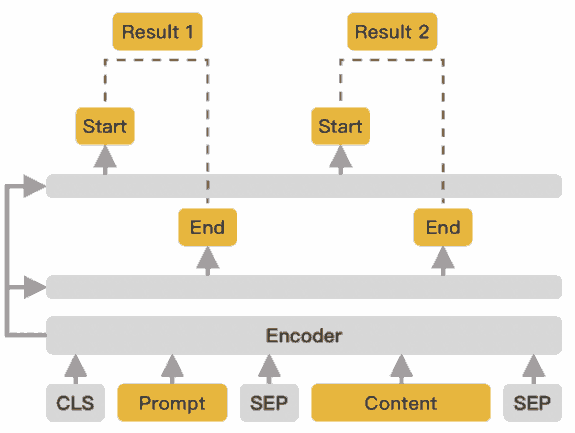
和原版不同, 他不是生成式, 而是用指针得出实体的首尾 index. 实际上就是标准的机器阅读理解, question + text -> answer (原版 BERT 给的 question answering 例子). 比原版 BERT 的优势大概是对中文信息抽取任务有优化 (预训练层面). 做法类似香侬的
- Li, X., Feng, J., Meng, Y., Han, Q., Wu, F., & Li, J. (2019). A unified MRC framework for named entity recognition. arXiv preprint arXiv:1910.11476. [Code]
- 周俊贤. (2022). 有哪些比 BERT-CRF 更好的 NER 模型?
「对白」在做商品描述属性挖掘时也用到了 BERT-MRC, 见 这里.
UIE 的做法是把 schema 拆成单独的问题, 每次调用模型只输入一个问题 (字段), 输出一个回答, 因此字段多时效率有问题 (原版生成式也有慢的问题).
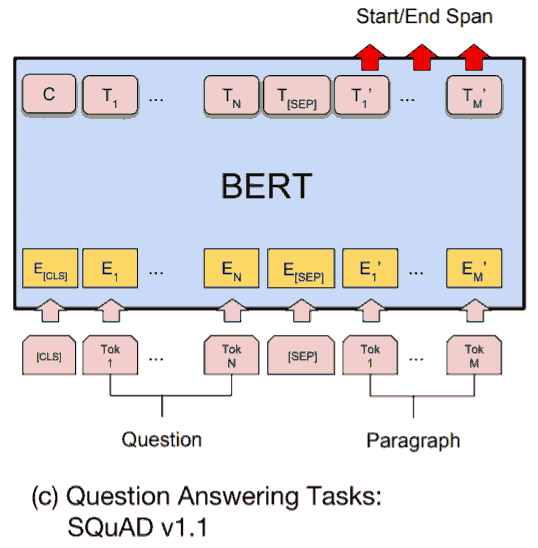
# model_zoo/uie/model.py
class UIE(ErniePretrainedModel):
def __init__(self, encoding_model):
super(UIE, self).__init__()
self.encoder = encoding_model
hidden_size = self.encoder.config["hidden_size"]
self.linear_start = nn.Linear(hidden_size, 1)
self.linear_end = nn.Linear(hidden_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, input_ids, token_type_ids, pos_ids, att_mask):
sequence_output, pooled_output = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
position_ids=pos_ids,
attention_mask=att_mask
)
start_logits = self.linear_start(sequence_output)
start_logits = paddle.squeeze(start_logits, -1)
start_prob = self.sigmoid(start_logits)
end_logits = self.linear_end(sequence_output)
end_logits = paddle.squeeze(end_logits, -1)
end_prob = self.sigmoid(end_logits)
return start_prob, end_prob
结构没什么特别的 (Show more »)
# medium
UIE(
(encoder): ErnieModel(
(embeddings): ErnieEmbeddings(
(word_embeddings): Embedding(40000, 768, padding_idx=0, sparse=False)
(position_embeddings): Embedding(2048, 768, sparse=False)
(token_type_embeddings): Embedding(4, 768, sparse=False)
(task_type_embeddings): Embedding(16, 768, sparse=False)
(layer_norm): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(encoder): TransformerEncoder(
(layers): LayerList(
(0): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(1): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(2): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(3): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(4): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(5): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
)
)
(pooler): ErniePooler(
(dense): Linear(in_features=768, out_features=768, dtype=float32)
(activation): Tanh()
)
)
(linear_start): Linear(in_features=768, out_features=1, dtype=float32)
(linear_end): Linear(in_features=768, out_features=1, dtype=float32)
(sigmoid): Sigmoid()
)
他在模型外面接了两个全连接层, 分别输出每个 token 是实体开头和实体结尾的概率.
他实现的解码方式是, 考虑概率超过阈值的 index, 以实体结尾指针开始往前找到最近的实体开头指针, 绑定这两个指针对应的实体. 可见现在的方式无法处理嵌套实体 (指同一个字段实体嵌套).
从他的源码实现看, 最后模型输出的实体附带的概率是头指针和尾指针概率的乘积.
ERNIE
因为上面实现的 UIE 本质上和 BERT 阅读理解一样, 所以还是讲讲 ERNIE.
1.0

ERNIE 1.0 除了中文 BERT 的字 mask 外, 还加上了词 (实体和词组短语) mask. (英文本来就是词 mask.)
- Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., … & Wu, H. (2019). Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.
2.0
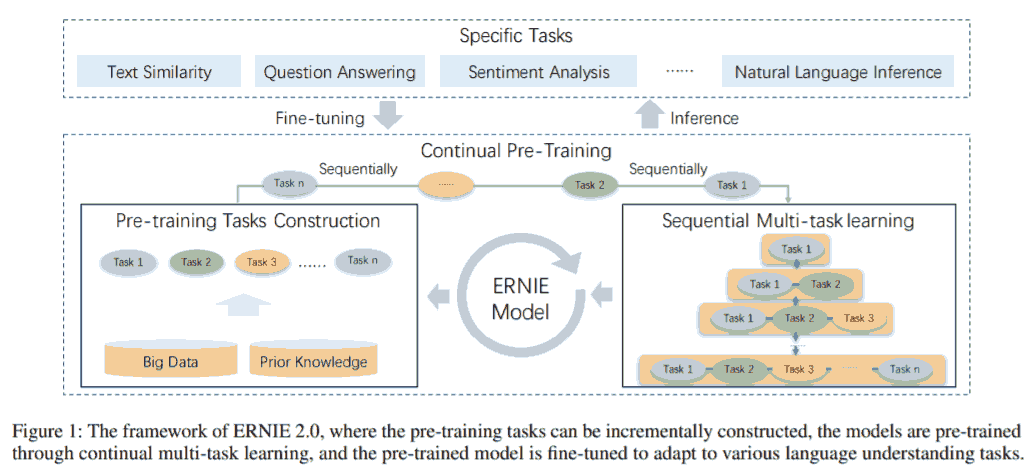
ERNIE 2.0 多任务贯序持续学习, 加入了 task embedding. 维持老任务的基础上持续增加任务是为了避免 “遗忘知识” (而传统的 continual learning 会遗忘知识).
Whenever a new task comes, the continual multi-task learning method first uses the previously learned parameters to initialize the model, and then train the newly-introduced task together with the original tasks simultaneously.
One left problem is how to make it trained more efficiently. We solve this problem by allocating each task N training iterations. Our framework needs to automatically assign these N iterations for each task to different stages of training.
上面这段挺怪的, 没看出怎么更有效了.
Although multi-task learning from scratch could train multiple tasks at the same time, it is necessary that all customized pre-training tasks are prepared before the training could proceed.
这段感觉也有点牵强.
- Sun, Y., Wang, S., Li, Y., Feng, S., Tian, H., Wu, H., & Wang, H. (2020, April). Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 05, pp. 8968-8975).
3.0
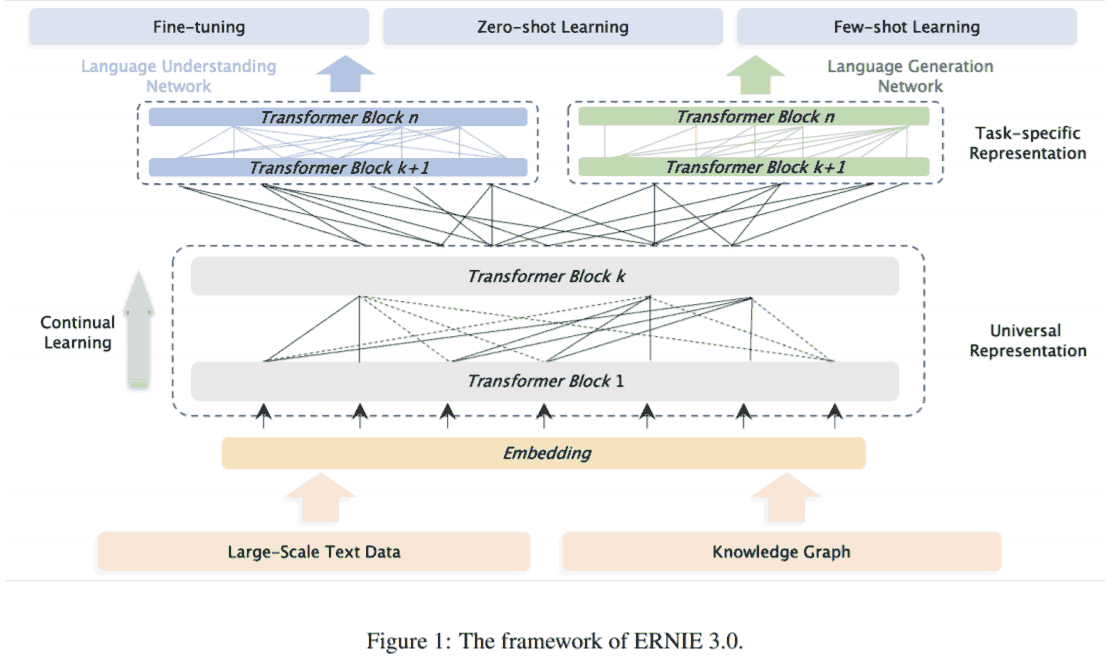
Inspired by the classical model architecture of multi-task learning, in which the lower layers are shared across all tasks while the top layers are task-specific, we proposed the ERNIE 3.0 to enable the different task paradigms to share the underlying abstract features learned in a shared network and utilizing the task-specific top-level concrete features learned in their own task-specific network respectively.
用的 transformer 都是 multi-layer Transformer-XL (适应长文本). 此外 3.0 比 2.0 新增的是预训练任务 universal knowledge-text prediction, 加入了知识图谱.
Given a pair of triple from knowledge graph and the corresponding sentence from encyclopedia, we randomly mask relation in triple or words in a sentence. To predict the relation in the triple, the model needs to detect mentions of head entity and tail entity and determine semantic relationship that holds between them in the corresponding sentence. Meanwhile, to predict words in the corresponding sentence, the model not only considers the dependency information in the sentence, but also logical relationship in the triple.
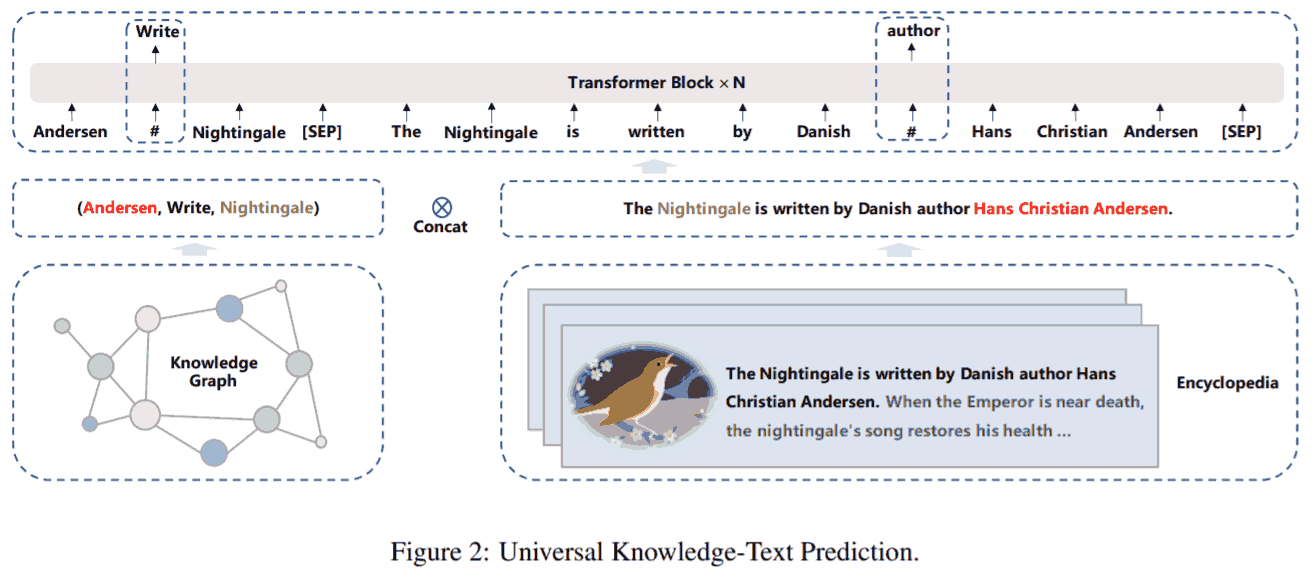
- Sun, Y., Wang, S., Feng, S., Ding, S., Pang, C., Shang, J., … & Wang, H. (2021). Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137.
Bert 和 Ernie 是同一个系列剧的主角, 结果清华也有同名模型 ERNIE, 从略.
- ERNIE 官方文档
- 徐土豆. (2021).『清华ERNIE』 与 『百度ERNIE』 的爱恨情仇
- 段易通. (2019). BERT 与知识图谱的结合——ERNIE 模型浅析
杂项
分句小脚本
处理引号内标点等问题.
# taskflow/utils.py#L105-L114
def cut_chinese_sent(para):
"""
Cut the Chinese sentences more precisely.
reference https://blog.csdn.net/blmoistawinde/article/details/82379256
"""
para = re.sub(r'([。!?\?])([^”’])', r'\1\n\2', para)
para = re.sub(r'(\.{6})([^”’])', r'\1\n\2', para)
para = re.sub(r'(\…{2})([^”’])', r'\1\n\2', para)
para = re.sub(r'([。!?\?][”’])([^,。!?\?])', r'\1\n\2', para)
para = para.rstrip()
return para.split("\n")
我改写成了
def split_sents(para: str) -> List[str]:
"""
在需要分句的地方加上换行符 `\n`, 最后据此分句. 考虑了引号.
ref https://blog.csdn.net/blmoistawinde/article/details/82379256
"""
delimiters = r';;。!?\?' # 加上分号
commas = ',,'
right_quotes = r'”’'
para = re.sub(fr'([{delimiters}])([^{right_quotes}])', r'\1\n\2', para)
para = re.sub(fr'(\.6)([^{right_quotes}])', r'\1\n\2', para)
para = re.sub(fr'(\…2)([^{right_quotes}])', r'\1\n\2', para)
para = re.sub(fr'([{delimiters}][{right_quotes}])([^{commas}{delimiters}])', r'\1\n\2', para)
para = para.rstrip()
return para.split("\n")
用 Pinferencia 搭建 demo
是从 这里 看到的. 好处是真的很便利, 不过当然没有任何优化.
Pinferencia 是国人开发的尚不成熟的用于快速搭建服务的 python 库. 做 demo 不错. 里面用到的 uvicorn 语法可以参考 这里.