弱监督旨在避免昂贵的大量手动标注, 而采用编程式的方法生成标注数据. 一般分为两步: 先用「多种来源的带噪声标注规则」(称为 labelling functions) 对「无标注数据」进行标注 (得到 label model), 再把 (用 label model) 生成的标注数据喂给下游模型 (end model) 训练. 理想是 label model 可以泛化 (处理冲突, 平滑标签) labelling functions, 然后 end model 进一步泛化. (依然需要一些标注数据作为验证集和测试集以评估效果.)
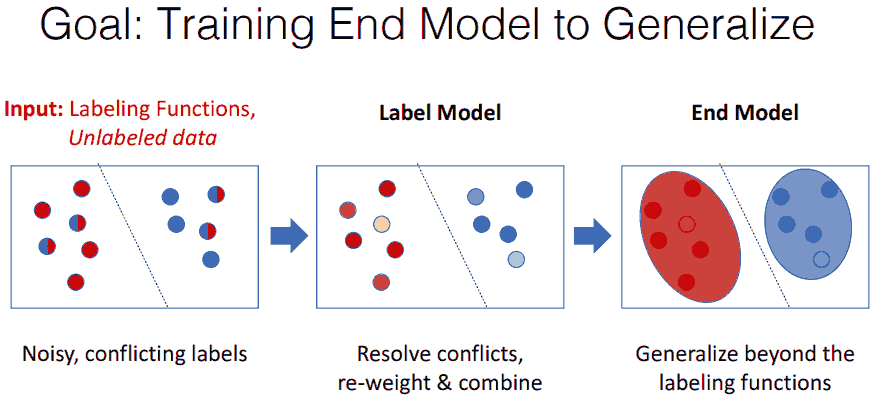
用编程式的方法生成训练数据的好处
- 可以更快地生成标注数据, 向模型注入人工干预.
- 如果后续标注规则需要调整, 也能更系统地修改标注.
于是可能适用的场景
- 无标注数据, 需要快速冷启动.
- 已经积累了规则模型, 想要泛化.
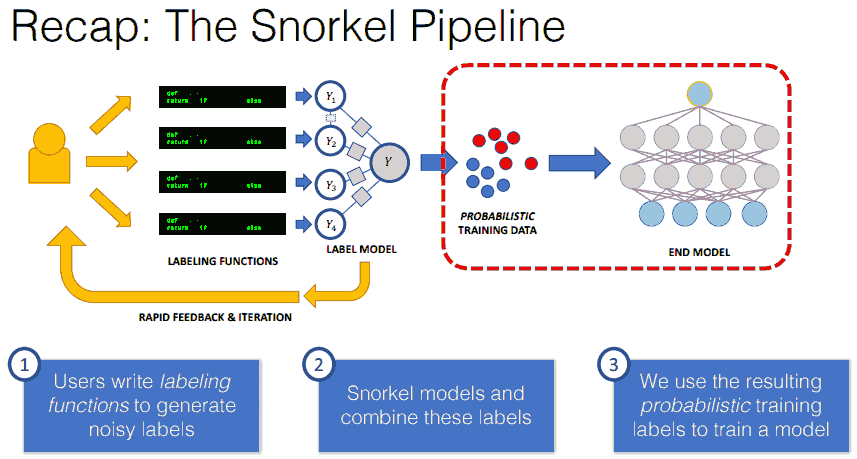
下面以 Snorkel 和 Skweak 为例, 介绍方法.
- Ratner, A., Bach, S. H., Ehrenberg, H., Fries, J., Wu, S., & Ré, C. (2017). Snorkel: Rapid training data creation with weak supervision. Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, 11(3), 269. [Code]
- Lison, P., Barnes, J., & Hubin, A. (2021). skweak: Weak Supervision Made Easy for NLP. arXiv Preprint arXiv:2104.09683. [Code]
- Lison, P., Hubin, A., Barnes, J., & Touileb, S. (2020). Named entity recognition without labelled data: A weak supervision approach. arXiv Preprint arXiv:2004.14723.
Labelling functions
首先通过多个打标函数 (labelling functions) 对数据标注, 比如
- 手写的规则, 正则表达式
- 远程监督, 领域词典, 外部知识库
- 弱学习器, 在领域外训练过的模型
- 文档级函数: 解决文档内的标注一致性问题 (见 skweak 原文)
每个函数对样本生成一种标注, 只关注数据的某些方面, 只标注部分数据 (low coverage). 每个样本会得到多个可能会冲突的标注, 将这些标注聚合起来学习一个打标模型 (label model) 以得到最终的标注.
Label models
打标模型是生成式模型, Snorkel 和 Skweak 的打标模型略有不同.
Snorkel
We model the true class label for a data point as a latent variable (因为不知道真实标签) in a probabilistic model. In the simplest case, we model each labeling function as a noisy “voter” which is independent. We can also model statistical dependencies (见原文 3.2 Modeling Structure) between the labeling functions to improve predictive performance.
为什么需要打标模型, 而不是同一个样本的多个标签直接 majority vote? 理想是打标模型能泛化打标函数. 另一个显而易见的原因是打标函数之间可能有相关关系, 导致投票不公平.
While the generative model is essentially a re-weighted combination of the user-provided labeling functions–which tend to be precise but low-coverage–modern discriminative models can retain this precision while learning to generalize beyond the labeling functions, increasing coverage and robustness on unseen data.
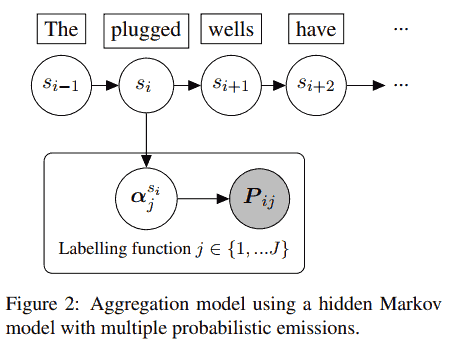
图中间的 label model 是一个概率模型 (因子图), 其中真实标签 $Y$ 是隐变量, 图上有 4 个打标函数 (得到 4 个标签), 其中第 1 个和第 2 个打标函数之间有依赖关系, 其他打标函数互相条件独立 (given 真实标签). 最后聚合得到的标签 $\tilde Y$ 是概率标签 (随机变量), 下游模型 (end model), 最小化损失函数的期望
\[\min_\theta \sum_{i=1}^n \operatorname{\mathbb E} l(h_\theta(x_i), \tilde Y_i),\]其中 $x_1,\dots,x_n$ 是输入数据, $h$ 是模型, $\theta$ 是模型参数, $l$ 是损失函数, 期望是对随机变量 $\tilde Y$ 求的.
A formal analysis shows that as we increase the amount of unlabeled data, the generalization error of discriminative models trained with Snorkel will decrease at the same asymptotic rate as traditional supervised learning models do with additional hand-labeled data
另外原文 3. WEAK SUPERVISION TRADEOFFS 介绍了 (经验上) 什么时候用 label model 会好于 majority vote.
Skweak
Snorkel 在理念上没有考虑序列标注问题, skweak 则补上个这一点. 打标模型是隐 Markov 模型, 其中真实标签是隐变量, 隐变量序列构成一个 Markov 链 (Snorkel 假设隐变量都是独立的, 没考虑序列关系), 标注函数 given 真实标签后条件独立.
Performance
 outperforms distant supervision baselines, and approaches hand supervision.")
 on NER. 可以看出一个问题是, 后接的下游模型反而不如直接用打标模型.")
有人做了一个综合的评测
- Zhang, J., Yu, Y., Li, Y., Wang, Y., Yang, Y., Yang, M., & Ratner, A. (2021). WRENCH: A Comprehensive Benchmark for Weak Supervision. arXiv Preprint arXiv:2109.11377.

他们得到的一些结论
- For end models, surprisingly, directly training a neural model with weak labels does not guarantee the performance gain.
- Strong weakly supervised models rely on high-quality supervision sources. Both label model and end model perform well only when the quality of the overall labeling functions is reasonably good. 基本是废话, 毕竟 garbage in, garbage out.
- For sequence tagging tasks, selecting appropriate tagging scheme is important. choosing different tagging schema can cause up to 10% performance in terms of F1 score. This is mainly because when adopting more complex tagging schema (e.g., BIO), the label model could predict incorrect label sequences, which may hurt final performance especially for the case where the number of entity types is small (TODO: 为什么?). Under this circumstance, it is recommended to use IO schema during model training.
- For sequence tagging tasks, CHMM gains an advantage over other baselines in terms of label model.
CHMM: Conditional hidden Markov model substitutes the constant transition and emission matrices by token-wise counterpart predicted from the BERT embeddings of input tokens. The token-wise probabilities are representative in modeling how the true labels should evolve according to the input tokens.
出自
- Li, Y., Shetty, P., Liu, L., Zhang, C., & Song, L. (2021). BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition. arXiv preprint arXiv:2105.12848.
A few last comments
可以把 label model 看成模型集成, 而 labeling functions 则为弱分类器, 希望它们数量多, 互相有差别而且准确率不低. Snorkel 做了这些事情.
- 把集成用在标注数据上.
- 用因子图聚合标签. 但他文中其实对这一块讲得比较少, 这个生成模型几版论文好像又变了很多方案 (现在的开源版本基于 matrix completion, 更 scalable), 我没仔细读, 无法评价.
- 数学证明在一定 setting 下, 弱监督可以接近强监督.
Google AI 博文 Harnessing Organizational Knowledge for Machine Learning 介绍了他们的弱监督部署经验, 提到可以用不适合放在生产端的资源 (resources that are too slow (e.g. expensive models or aggregate statistics), private (e.g. entity or knowledge graphs), or otherwise unsuitable for deployment) 标注数据, 然后用便宜, 实时的特征训练, 在生产端预测, 达到 “知识迁移” 的效果. 用一套特征标数据, 用另一套特征训练. “This cross-feature transfer boosted our performance by an average 52% on the benchmark datasets we created.”
文本分类特别契合 “用一套特征标数据, 用另一套特征训练” 的过程, 比如用一些规则标数据, 再用语言模型训练.
Skweak 就是在 snorkel 的基础上套一层 HMM 罢了.
大量高质量的有标注数据依然是成功的关键. 在有充足数据但标注数据少的时候, Snorkel 是一个比较直观可控的 (通过 labeling functions) 可能带来提升的方式, 可以尝试.
Further reading
- Snorkel 是 Stanford 一个专注于 data-centric 团队 Hazy Research 的工作, 有商业化产品 Snorkel AI. 它的前身是 DeepDive (因此也用了个潜水相关的词). Skweak 目前影响力有限.
- 官方 tutorial 中推荐 这个.
- 关联资源见 这里, 它的 blog 介绍了很多后来添加的新功能, 包括数据增强, slice 等.
- 作者 Ratner 2019 年的 博士论文, 大合集. Snorkel 后续好像没什么新消息了.
- 虽然论文中没提 NER, 但是他家有 NER 产品.
- Snorkel 团队有 2017 年的文章 SwellShark 做 NER, 代码没有开源. 对嵌套实体用了基于多项分布的 label model, 最后 end model 用的还是 LSTM-CRF, 提升有限, 参考价值有限.
- Fries, J., Wu, S., Ratner, A., & Ré, C. (2017). Swellshark: A generative model for biomedical named entity recognition without labeled data. arXiv Preprint arXiv:1704.06360.
- Case studies for Google, Intel, and IBM
- rubrix, open-source framework for data-centric NLP. Data annotation and monitoring for enterprise NLP (2021 年中新出的)
- Jay. (2021, Aug 26). 弱监督学习框架 Snorkel 在大规模文本数据集 “自动标注” 任务中的实践. 携程技术.
- JayJay. (2021, Jan 23). 工业界如何解决 NER 问题? 12 个 trick, 与你分享~.
- “NER 本质是基于 token 的分类任务, 对噪声极其敏感. 如果盲目应用弱监督方法去解决低资源 NER 问题, 可能会导致全局性的性能下降, 甚至还不如直接基于词典的 NER.”
- Issue #1254: How to create training data for NER task using snorkel? 其实并不自然. 另外目前两个框架都不能覆盖关系抽取任务, 只能用来做关系分类 (把实体对作为输入).
- Issue #803: Question: Has anyone used snorkel for tabular numerical data?
- 为什么主动学习 (active learning) 不温不火: 温文的回答
- Probabilistic Inference and Factor Graphs - DeepDive
Image sources
- Ratner, A. (2018, Aug 28). Snorkel Rapidly Creating Training Sets to Program Software 2.0 [Slides].
- Ratner, A., Bach, S., Varma, P., & Ré, C. (2017, Jul 16). An overview of weak supervision [Blog post]. snorkel.