主要介绍 DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks, 其他方法暂时略讲. 附带讲一些我知道的统计学领域的方法. 例子依然主要以销量预测为例.
Model
尽量和原论文记号保持一致. 假设我们有 $N$ 条时间序列, $T$ 个时间点. 第 $i$ 条时间序列在时间 $t$ 的值记为 $z_{i, t}$, 特征记为 $x_{i,t}$ (向量). 为了符号简便, 去掉下标 $i$, 简记为 $z_t$, $x_t$. 记
\[z_{t_1:t_2} := (z_{t_1}, z_{t_1+1},\dots, z_{t_2})\]为时间段 $[t_1, t_2]$ 的序列. 类似地定义 $x_{t_1:t_2}$, 并假设特征在所有时间点 (包括未来) 都是已知的. 假设历史序列时间段为 $[1, t_0-1]$, 未来为 $[t_0, T]$, 我们要建模条件似然
\[P(z_{t_0:T} | z_{1:t_0-1}, x_{1:T}).\]假设模型的条件似然为
\[Q_\Theta(z_{ t_0:T} | z_{1:t_0-1}, x_{1:T}) = \prod_{t=t_0}^T Q_\Theta(z_{t} | z_{1:t_0-1}, x_{1:T}) = \prod_{t=t_0}^T \ell(z_{t}|\theta(h_{t}, \Theta)),\]其中 (省略 $h$ 下标 $i$)
\[h_t = f(h_{t-1}, z_{t-1}, x_t, \Theta),\]而 $f$ 表示多层 LSTM, 似然 $\ell$ 是根据指定的参数分布来取的 (如 Gauss, negative binomial).
生成预测样本的方法是迭代式 (很常见的做法): 根据选定的参数分布 sample 出一个值, 之后将这个值当成真实值继续 sample 下一个时间点的样本. 重复若干次, 再根据多条模拟样本估计感兴趣的分位数.
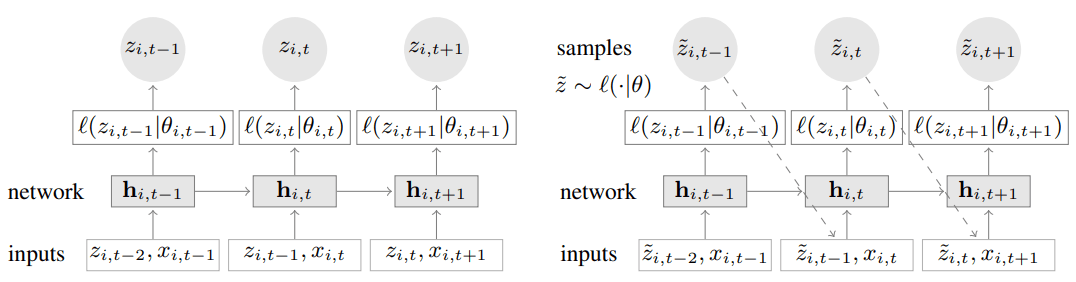
Training
Gauss 和 negative binomial 分布可以用一阶矩和二阶矩完全刻画, 神经网络干的事情就是学习这俩参数. 目标是极大化 log 似然
\[\sum_{i=1}^N\sum_{t=t_0}^T \log \ell(z_{i, t}|\theta(h_{i,t})).\]特征: 价格, 促销, ‘age’ (the distance to the first observation in that time series), day-of-the-week, category embedding 等.
Data Augmentation
类似 cross-validation, 用一个 window 去截时间序列.
- 比如 $t=1$ 可以从不同的时间点开始. 但是整个序列的长度依然保持为 $T$.
- 起始点 $t=1$ 可以放在最早的历史时间点之前, 用零填充. 这样可以让模型学到新序列的行为. (冷启动)
- 这样数据增强的目的是保证绝对时间的信息只能通过特征学到, 而不是根据 $z_t$ 在时间序列中的相对位置.
Scale Handling
- 对参数进行 item-dependent 的 scale $\nu_i$, 便于对不同 scale 的时间序列的学习.
- 序列不平衡. 有少量的物品销量会很大, 而销量大的物品和销量小的物品行为可能不同. 由于使用的是随机梯度下降, 如果我们均匀地从时间序列中抓几条来更新参数, 可能会导致销量大的物品欠拟合. 论文作者采用的方法是以学习到的 scale $\nu_i$ 作为权重进行采样, 这样销量大的物品会被多关照一些.
- 直接用均值作为 $\nu_i$ 在实际中效果不错.
State-Space Model
模型结构很简单, 就是常见的 RNN 变种. AR (autoregressive) 就在于上一个时间点的真值会被用来预测当前时间点的值.
总得来说就是假设时间序列的条件分布服从某个参数分布, 而这个参数是用神经网络学来的, 目标是最大化条件似然. 整个结构实际上就是统计学中 state space model 的结构, 唯一区别在于 $f$ 被换成了神经网络. 实际上也有直接标题为深度学习 ssm 的文章 Deep State Space Models for Time Series Forecasting, 但我还没读.
说回统计学, 在 Some Evaluations for Time Series Forecasting 里提到过销量属于计数时间序列, 关于计数时间序列的状态空间模型, 可以参考
- Davis, R. A., Holan, S. H., Lund, R., & Ravishanker, N. (Eds.). (2016). Handbook of discrete-valued time series. CRC Press.
专著, Davis 是老时间序列专家了. 一些综述可以在这里找到.
- Davis, R. A., & Liu, H. (2016). Theory and inference for a class of nonlinear models with application to time series of counts. Statistica Sinica, 1673-1707.
这篇我觉得证明很漂亮.
- Liu, M., Li, Q., & Zhu, F. (2019). Threshold negative binomial autoregressive model. Statistics, 53(1), 1-25.
比较近的文章, 综述可以一看.
统计学更注重证明相关性质: 参数估计的相合性, 渐进正态性等.
Implementation
在 深度需求预测 (Deep Demand Forecast) 中提到了几篇文章, 我看了作者关于 DeepAR 的 PyTorch 实现, 发现有明显的问题, 而且文章提到的一些 tricks 并没有实现. 后来看到了亚马逊的 gluonTS 包, 这里有一篇介绍 Neural time series models with GluonTS Time Series Workshop ICML 2019.
在 gluonTS 中, 其他深度时间序列的模型实现粗看都不如 deepar 的完整.
文档比较缺, 很多细节必须要读源码.
- time_features
- data aug
- hyper params tuning
- 官方教程里给出了定义 data transformation 的方法, 却从来没有用过它. 实际上各个 estimator 类都自带一个 transformer, 里面有一个 spliter 就是数据增强用的.
- LSTM 的 dropout 使用的是 mxnet 的 zoneout.
- 虽然在 data 中可以定义 feat_dynamic_cat, 但是模型并不能使用这个特征.