过年的时候第一时间读了论文, 但是笔记只写了一半. 回过头来, V3 和 R1 仍然是不能略过的经典之作.
V1~V3
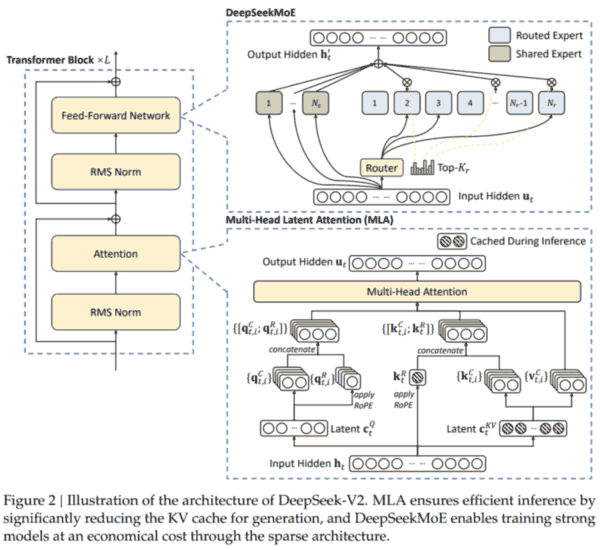
MoE
FFN 改进. DeepSeekMoE has two key ideas: segmenting experts into finer granularity for higher expert specialization and more accurate knowledge acquisition, and isolating some shared experts for mitigating knowledge redundancy among routed experts.

另外引入 auxiliary loss for load balance. 由三个 loss 相加: expert-level, device level, communication level. 每个 loss 由 fraction 与 probability 相乘求和.
MLA
Attention 改进. MQA 和 GQA 为了减少 KV cache 牺牲了太多性能. 而 MLA 通过低秩分解, 在减少 KV cache 的同时, 保持了更好的性能.
MHA: 原本第 $t$ 个 token 的 attention 层输入为 $h_t$, 分别经过三个矩阵 ($W^Q$, $W^K$, $W^V$) 变换成 $q_t$, $k_t$, $v_t$, 分成多头之后再算 attention, 最后输出再经过一个矩阵投影 $W^{O}$. 每层需要 2d 参数缓存 kv, 其中 d 为每个头的维度乘头的数量.
MLA: 先通过一个下投影矩阵将 $h_t$ 变为维度更小的 $c^{\mathrm KV}_t$, 然后用两个上投影矩阵 ($W^{\mathrm UK}$, $W^{\mathrm UV}$) 把 $c^{\mathrm KV}_t$ 变换成 $k_t$, $v_t$. 注意之后 qk 要做内积, 这里的 $W^{\mathrm UK}$ 可以吸收到 $W^Q$ 里; 同理 $W^{\mathrm UV}$ 可以吸收到 $W^{O}$ 中. 因此每层只需要缓存 $c^{\mathrm KV}$, 参数量大大减少. (此外对 $q_t$ 也做低秩分解: 将 $h_t$ 变成维度更小的 $c^{\mathrm Q}_t$, 再上投影为 $q_t$.)
但是 MLA 存 $c$ 的操作不兼容 ROPE. 因为 ROPE 和位置 $t$ 相关, 会导致 $W^{\mathrm UK}$ 无法吸收到 $W^Q$ 里 (变成与 $t$ 有关). 于是给 qv 引入了一些额外的维度, 专门做 ROPE. 每层额外再缓存一些 k 的维度即可.
MTP
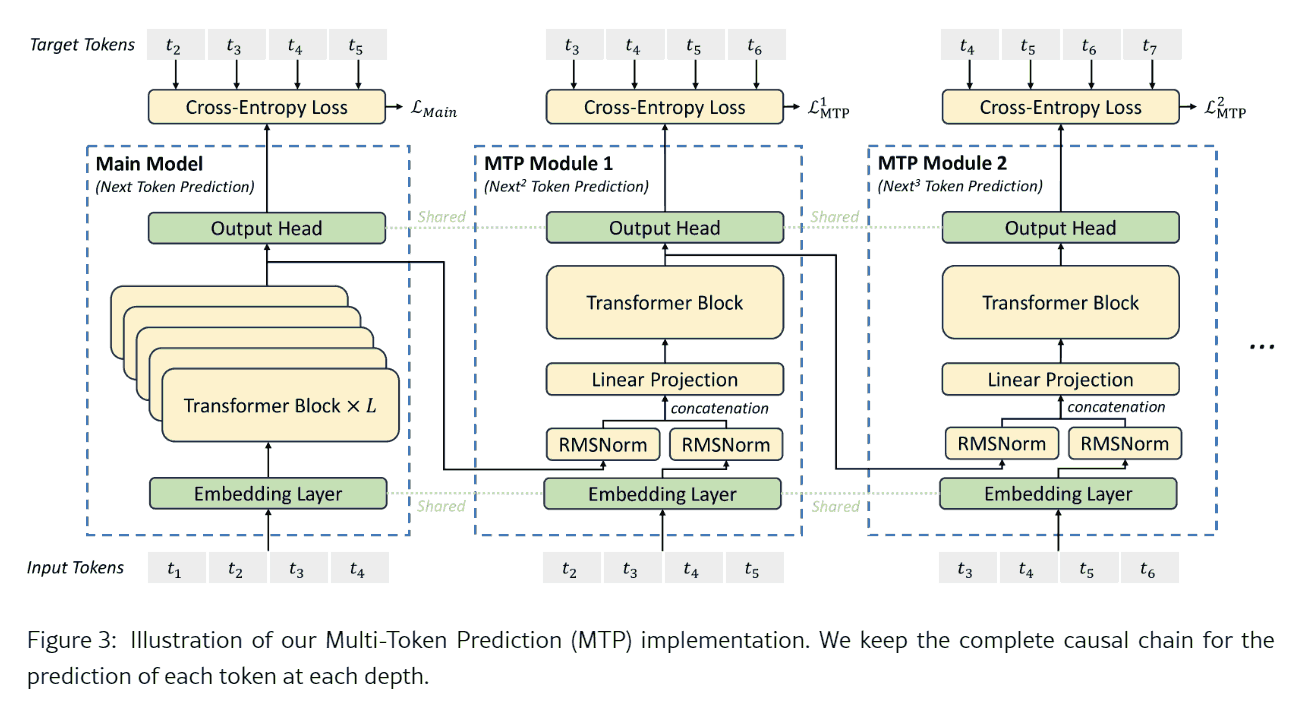
训练阶段用, 推理可关的辅助机制. 训练时是 casual 串行的. 预测时可以扔掉 MTP 或者用 MTP 做投机采样.
Instead of predicting just the next single token, DeepSeek-V3 predicts the next 2 tokens through the MTP technique. Combined with the framework of speculative decoding, it can significantly accelerate the decoding speed of the model. A natural question arises concerning the acceptance rate of the additionally predicted token. Based on our evaluation, the acceptance rate of the second token prediction ranges between 85% and 90% across various generation topics, demonstrating consistent reliability. This high acceptance rate enables DeepSeek-V3 to achieve a significantly improved decoding speed, delivering 1.8 times TPS (Tokens Per Second).
其实 deepseek 只训了一个 MTP 头, 但是推理却用投机解码预测 next 2 tokens, 训推不一致, 但是采纳率还是很高.
Due to the fact that only a single layer of weights is exposed in DeepSeek’s MTP, the accuracy and performance are not effectively guaranteed in scenarios where MTP > 1 (especially MTP ≥ 3).